![]() ARM gave out some interesting server data the other day including some hard numbers from Paypal. It may not be as detailed as SemiAccurate likes but it is the best we have so far.
ARM gave out some interesting server data the other day including some hard numbers from Paypal. It may not be as detailed as SemiAccurate likes but it is the best we have so far.
There were actually two data sets given, one for ARM’s internal DSG group and the other the aforementioned Paypal data. Both were very enlightening but come with a caveat or 12. Keep the fine print in mind when going over these numbers, it makes a big difference. Even with that in mind, for the workloads given, ARM servers look like a pretty clear win.
The first workload was ARM’s DSG group which does Linux and tool chain development. To do a complete build of everything the ‘old way’, presumably on x86 machines, took 10 weeks. This is a massive chain of tools, OSes, and lots and lots of accompanying programs but that is still a long time. Part of this was due to the cross-compilation aspect of the work, compiling native ARM ISA tools on an x86 box can take a bit more time than native on native. While it wasn’t stated I would also bet that the compiler farm used had rotating disks.
DSG moved these tasks to an HP Moonshot with m400 cartridges using Applied Micro X-Gene SoCs. The raw data point is that the build time went from 10 weeks or 70 days to 2 days, a 35x reduction in build time. That is a pretty good number by any count no matter how it is achieved. What ARM did not discuss is the node counts before and after and most importantly the disk subsystems and/or memory per node. If these were the bottlenecks previously, either one could account for most of the difference.
That said the CPUs very likely made a big difference too, even if MIPS for the x86 and ARM cores stayed the same, native compilation would probably be a bit faster. Before you assign all of the improvement to one subsystem or another, let us just remind you that Redhat had similar if not quite so spectacular gains when they went to native ARM servers a few months back. They talked about it at an AMD ARM server event but I didn’t write down the raw numbers, sorry. That is the long way of saying the ARM DSG numbers are not a fluke, nor are they as far out of line as you might expect at first glance.
The other proof point, technically there were two, come from Paypal. They gave out a few numbers for real-time data analysis and traditional data center workloads. The data analysis was done on a Moonshot with an m800 cartridge bearing a TI Keystone II 66AK2H SoC, the data center workloads were done on an m400 with X-Genes. One thing to keep in mind is that the Keystones IIs are 32-bit devices with four 1GHz A15 cores backed by eight C66x DSPs, any guesses as to where the number crunching is done? The workload is described like this.
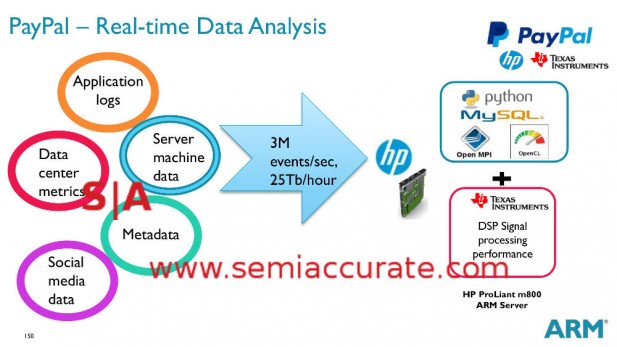
Paypal’s real-time workloads description
As you can see Paypal’s data analysis is labeled real-time and they mean it. While it wasn’t said, this probably includes not just questions like, “does the account have enough to do the transaction?”, but more likely encompasses fraud detection. That is a complex and proprietary calculation that needs to be done fast, really fast. If you swipe a credit card, how long does it take before you get annoyed at a lack of response? Seconds? Think about how much work needs to be done in that time and how sensitive it is. Sure the workloads listed above don’t mention such things but you can bet Paypal’s real-time needs include such things.
The net result of the move from x86 to ARM/TI/DSPs was a claimed 9x reduction in acquisition costs, 2x reduction in power consumption per year, and a 7x increase in node density per rack. Lets take a look at those numbers a bit closer. Acquisition costs are hugely important, we told you about Intel’s server CPU pricing here and that is probably a large part of this data point. That said data centers don’t look much at acquisition costs, they look at TCO, that is all that really matters in the end. If your cheaper server eats more power and takes more manpower to manage and run, you won’t sell many to this market. Alone acquisition costs are almost meaningless.
A large part of TCO is power used, over 3-5 years it may end up costing more than the hardware. That is where the second number, a 2x reduction in power used, makes a big difference. Power used plus acquisition costs are a huge portion of TCO, if management costs are roughly equivalent between the node types, ARM servers are a clean kill. The node density per rack being 7x higher for ARM servers is not necessarily a good thing, that could very well mean 7x more management time and attendant costs. We doubt it is anywhere near that number but it is likely higher than 7x less x86 nodes. All in all the ARM servers should have a much lower TCO than the Intel ones.
That brings us to the first of the fine print items, the node count per rack. If the Moonshot nodes are being compared to a traditional 1U 2S server, the 7x density improvement is about what you would expect. A compute power per rack or even a core count per rack comparison would be a much more realistic, the node density means roughly nothing in this context. It is akin to comparing cylinder counts on a Ferrari and a Mack truck as a proxy for cargo hauling capacity.
One more unusual caveat that makes a bit more difference, the workload. For real-time analytics, latency is king, it is about the only thing that matters. It came up during the briefing that Paypal needs to have a certain number of cores or nodes free and idle waiting for incoming work. This minimizes latency and is a big reason why you can get a credit card to validate or fail in seconds. How many cores Paypal needs to have in this idle pool was not disclosed but you can be sure it is only as many as absolutely necessary and is watched closely.
When you need X cores waiting for work in order to meet absolute and hard latency requirements, you need to do just that. Big cores can do much more than small cores but if your requirements are absolute idle as it was intoned that Paypal does, you are wasting a lot of performance. As long as a small core has enough horsepower to complete a task in the necessary time, you will need only as many as you do big cores. In essence a single idle big core will be equivalent to a single idle small core, quite the unusual scenario. This is exactly what we covered in our guide to evaluating microservers two years ago. In this case a small core is good enough, and it is a TCO comparison.
That is where the density and cost per node advantage of an ARM server comes into play, if you need X nodes, a cheaper and slower node will win as long as it can do the job in the required time. For Paypal it does. That is where a portion of the acquisition cost advantage comes from, it isn’t that per GFLOP the ARM cores are that much cheaper, but when idle cores are needed, and idle small ARM cores cost far less than an idle big Intel cores. All this said we think the ARM cores would still win this comparison, but with those caveats not in place the margins wouldn’t be quite so lopsided.
Why do we say that? If you look at the second workload, it is described as traditional data center tasks. Paypal defines this as, “firewall, VPN, LDAP, Kerberos, virtualized, etc.”, or about what you would expect for non-core compute tasks. To SemiAccurate this is a much fairer comparison than the real-time analytics data. The data presented are the same numbers as before, 1.8x less acquisition costs, 7x less power, and 10.4x higher node density. Note the changes in multiples.
Node density is absolutely meaningless in this case for the same reason as before. Acquisition costs go from 9x to 1.8x less for an ARM server, a much more representative number. You can read this as m400 cartridges cost a huge multiple of m800 cartridges, there were a lot of idle nodes in the real-time racks, or GFLOPS:GFLOPS, x86 is not that much more expensive than ARM. Without knowing for sure, our educated guess is that it is a combination of less disparity in rack count, node count is pointless, and needing more ARM nodes to make up for the lack of performance per socket compared to big x86 cores.
That said as long as management overhead is within reason, it is still a clean kill for ARM, and one with a lot less asterisks on the numbers. These may not be as lopsided as the real-time numbers, but they are still a clean kill. Why? Almost half the cost to buy ARM servers and 1/7th the cost to run, that is a massive difference. The cost to run disparity between the two workloads is probably due to the idle x86 nodes being very efficient when in sleep or idle modes, Intel does a really good job here. When running closer to TDP, it looks like ARM’s claim of performance per watt is solid but without much more data it is hard to say for sure. In any case this workload is much more representative of the real world and a clear win for ARM.
Note: The following is analysis for professional level subscribers only.
Disclosures: Charlie Demerjian and Stone Arch Networking Services, Inc. have no consulting relationships, investment relationships, or hold any investment positions with any of the companies mentioned in this report.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Announces their NXE: 5000 High NA EUV Tool - Apr 18, 2024
- AMD outs MI300 plans… sort of - Apr 11, 2024
- Qualcomm is planning a lot of Nuvia/X-Elite announcements - Mar 25, 2024
- Why is there an Altera FPGA on QTS Birch Stream boards? - Mar 12, 2024
- Doogee (Almost) makes the phone we always wanted - Mar 11, 2024