![]() ARM has introduced a new realtime core and architecture, lets welcome the new v8-R and Cortex-R52. If you are into realtime processors this is a big deal, if not, you will probably use one anyway.
ARM has introduced a new realtime core and architecture, lets welcome the new v8-R and Cortex-R52. If you are into realtime processors this is a big deal, if not, you will probably use one anyway.
Until now the -R line of ARM cores was based on the v7-R ISA with three prominent members, the R7 and R8 lines for storage and modem type work and the R5 for safety critical applications. The former pair needs hard realtime functionality, the latter needs that and safety critical certifications. While you want your HDD reads to be reliable, you want your antilock braking system to be a whole other level of reliable. And certified. And really mean it. Think ASIL-D and related safety specs for a starting point.
It is this latter arena where the new R52 core plays, it is a safety critical hard realtime core with the need for more performance without sacrificing reliability or functionality. The new v8-R ISA brings a lot to the table here in three main groups, added functionality, lowered latency, and ease of use. One thing that you probably assumed are 64-bit functions based on the v8- part but v8-R is still only 32-bit. In the world the -R cores play in this isn’t a problem at all, it isn’t and never will be a consumer oriented core.
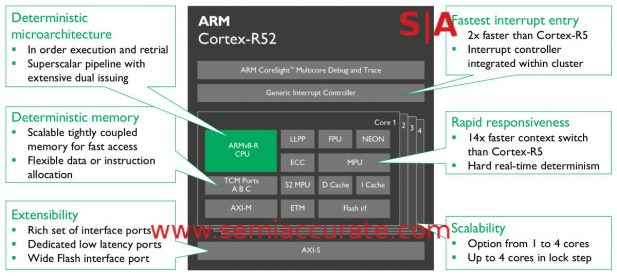
The block diagram of the Cortex-R52
On the surface the R52 looks pretty familiar, four clustered cores, AXI-4 bus, and bunch of memory options. When you dig a little deeper you start seeing differences like the debug and trace block plus an interrupt controller directly on the cluster of CPUs. Even with all of this, v8-R is code directly compatible with v7-R so no rewrite worries for your embedded and certified code. Lets take a look at the high points above and the difference a two makes when going from an R5 to an R52 other than the “up to 35%’ performance uplift”.
Update Sept 27, 2016@9:30am: Changed AXI-5 to AXI-4 which ARM says is correct.
First of all there is the deterministic architecture top to bottom which kind of necessitates in-order execution. The R52 is superscalar but it is still in-order so no problems there. What is a really odd addition for those coming from the -A or generalized CPU world is the deterministic memory portion. If you need realtime operation, memory accesses can be a problem. The R52 solves this by adding three TCM or Tightly Coupled Memory ports. If you have an SOC or system you can know your memory latency and adjust your code accordingly. This goes a long way towards a usable deterministic architecture and does a lot to fix memory latency. By fix we mean make consistent, not remove.
Latency is also addressed with the integrated interrupt controller on the cluster. ARM claims what was ~66 cycles of latency for an interrupt with an external IC is now ~27 cycles with the new way. If you think about how a realtime core works, basically sitting in a wait loop until it gets interrupted, this is a massive gain in performance for the system. Similarly a full context switch for a core is now a huge 14x faster than before. More interestingly this latency reduction is not code visible so no changes needed there. Changes in this realm are both costly and require re-certification so again this is a huge win.
On the functionality side there are a lot of improvements too, starting with added crypto instructions. This is necessary to prevent government agencies from illegally recording your antilock brake controller to dashboard blinky-light data stream. That is a joke but we assume there is a need for encryption on a lot of safety critical devices, with the R52 core you now have it along with a few lesser added instructions.
A lot of the new functionality comes from a new privilege level called EL2 which essentially allows v8-R devices to run a hypervisor. We won’t go into why a hypervisor is useful in this realm, it should be pretty obvious. One thing it does do is allow non-realtime and non-safety critical code to run on the same SoC without as much fear but there are probably much better ways to accomplish the same goal. Since the R52 has an AXI-5 bus, you could just add a -M or -A class cluster on the bus and run your movies or infotainment system on that.
Four cores plus a hypervisor in a realtime system essentially equals four discrete systems with nearly ironclad process separation, a really good basis for backup processes, checksums, multiple iterations of the same thing for failovers. Going one step further ARM has put lockstep modes in R52 so you can have two cores each with a shadow core running automatically. Once again this will save SoC designers a lot of headaches because it is not only done for them but done in a standardized way. One thing the R52 can not do is operate in 3-way lockstep for voting type operations but if you need it, you can implement it yourself.
The ease of use bit is a little harder to explain if you are not familiar with realtime cores and programming. In this world code is chunked into regions which are effectively hard separated from each other. You don’t really switch tasks as much as you interrupt something and do a process and go back to waiting on another interrupt. Code is more discrete chunks which define a single task rather than a monolithic blob of everything and the kitchen sink.
To address the ease of use side of this world, the v8-R ISA has made the code regions a lot easier to use. It starts with more flexible region sizes so your code is more likely to live in one region now where it may have had to span multiple regions before. Better yet regions had to be page aligned on v7-R and before, now they only need to be on 64-byte boundaries. This change may require recoding and recertification to take advantage of, but it will simplify the result and make maintenance and updates easier. One time pain, long-term big gains.
The trend is obvious
As you can see from the diagram above, in cars code complexity is linearly related to rim diameter which has been increasing rapidly. Seriously though you probably understand why we are on the verge of an explosion in realtime code complexity, ADAS, self-driving, AI based devices, and lots more mean this exponential rise in code, more importantly safety certified realtime code, is not going to slow down any time soon.
To address this, ARM introduced v8-R and the first v8-R core, the Cortex-R52. It may not be 64-bit like v8-A but it doesn’t need to be. What it does need to bring to the table is more performance, lower latencies, and ease of use/programming. It looks like ARM has delivered nicely on all three of these goals for their new ISA and core. With luck your next car will use one and automatically drive to you home rather than through your home.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026