![]() Today Marvell releases their Octeon 10 line of DPUs and they pack a bunch of interesting features. SemiAccurate didn’t see any major paradigm changes, just more of what you know and like about the Octeon family.
Today Marvell releases their Octeon 10 line of DPUs and they pack a bunch of interesting features. SemiAccurate didn’t see any major paradigm changes, just more of what you know and like about the Octeon family.
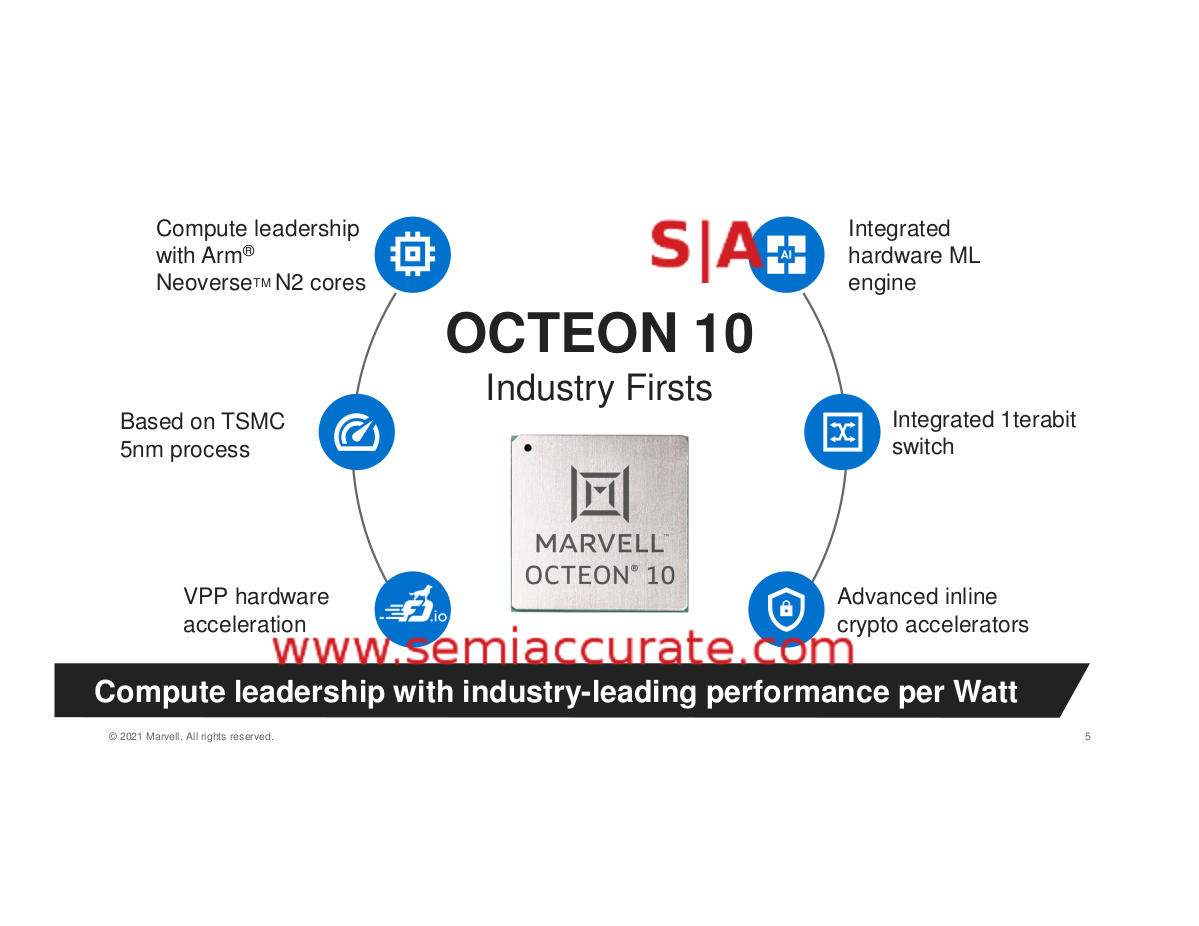
At a high level, the Octeon 10 line is an ARM Neoverse N2 cored SoC with all the telco, security, and networking accelerators built in. If that isn’t enough, Marvel threw in their switch block so you have 16x 50GbE ports available on top of that. If you haven’t been paying attention, this fits the definition of DPU, basically CPU + accelerators + high speed IO that is being tagged to everything of late but in the case of the Octeon 10, it fits rather nicely.
Octeon 10 at a high level
As you can see from this high level overview, the Octeon 10 hits most of the major talking points for a modern networking SoC. It is being built on TSMC’s 5nm process, first silicon is in the fabs as I write this, and chips are expected to sample in 2H/21. It will also be one of the first devices bearing the N2 cores on the market, plus the now ubiquitous AI hardware that no modern device is complete without. It all looks like this.

Octeon 10 block diagram
There are a lot of goodies in this diagram starting with the fanless bit under TSMC 5nm. The smallest CN103XX can run as low as 10W meaning it will fit nicely on a PCIe card, PCIe5 in this case. That puts Octeon 10 among the first PCIe5 devices out there, not that there will be anything to plug your sample in to but that isn’t Marvell’s fault. In any case you actually need that speed if you have any hope of feeding a 400GbE port, the 16Gbps/lane of PCIe4 mean 256Gbps best case.
The ARM N2 cores are fairly vanilla, 1MB of L2/core backed by 2MB of L3/core. This may not sound very impressive but Marvell has always done some neat things with system level caching on Octeon and related products and this time is no exception. While we didn’t get the full details of the caches, just keep in mind that there are a lot and they are tuned to reduce system latency. There are 2x128b SVE2 pipes as well plus the cores still have the 32b hardware should you need it. As a geeky aside, 32b can directly address 4GB of memory or 1/12th of a second worth at 400Gbps. Last up is DDR5/5200 support, up to 12 channels for the biggest SKU so memory throughput isn’t going to be a big bottleneck on the Octeon 10.
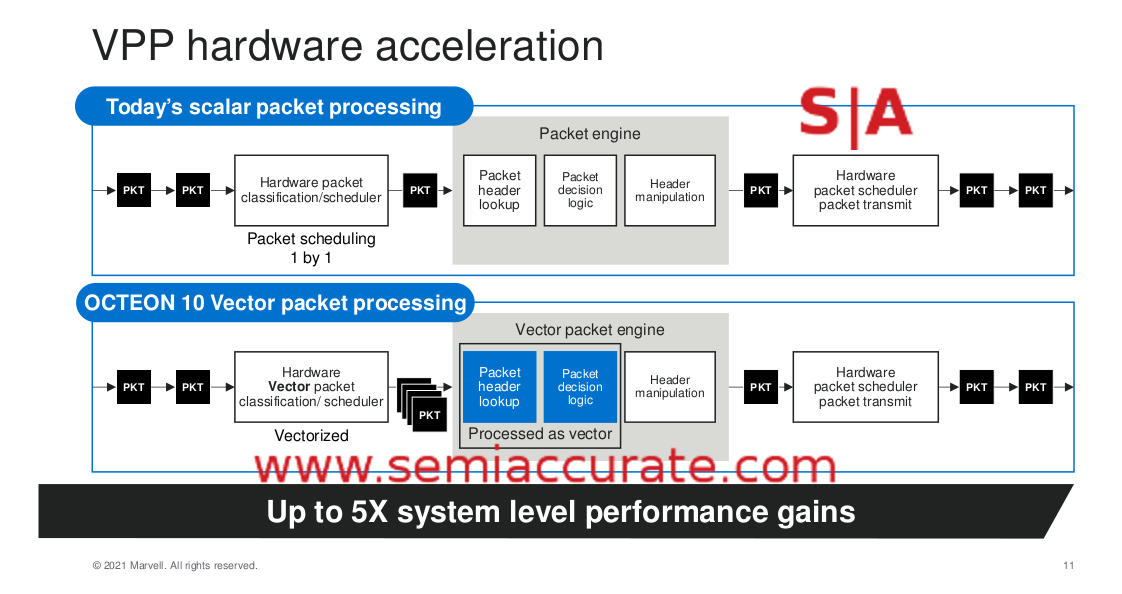
VPP is now in hardware
One of the more interesting accelerators is the VPP or Vector Packet Processing engine. What this does is batch multiple packets and process them at once as a vector. This SIMD processing means you only have to do one setup and a single set of loads for multiple packets rather than one for each packet saving a lot of time. Marvell says the latency gain from batching is more than made up for by the added efficiency of the single setup so it is a clear win. VPP isn’t new to the Octeon line however but this is the first time Marvell has put much of the functionality directly in hardware.
Next up we have the AI hardware and like several others it is a tile based architecture meaning it can scale up or down in area/performance as is needed for each device. Each tile has it’s own SRAM and MACs which supports INT8 and FP16 operation. More importantly the AI block is, “Directly in the data pipeline”, not an offload/accelerator in the traditional PC sense. This likely leads to very low latency for AI operations which is necessary in a throughput oriented device.
The last accelerator is of course crypto and Marvell has been doing this for a long time, in their Cavium guise they had the first one the author can remember seeing. This time around the Octeon 10 implements most of IPSEC in hardware which greatly reduces the compute overhead and CPU intervention. Nothing great changes this time around, it is just faster and more efficient.
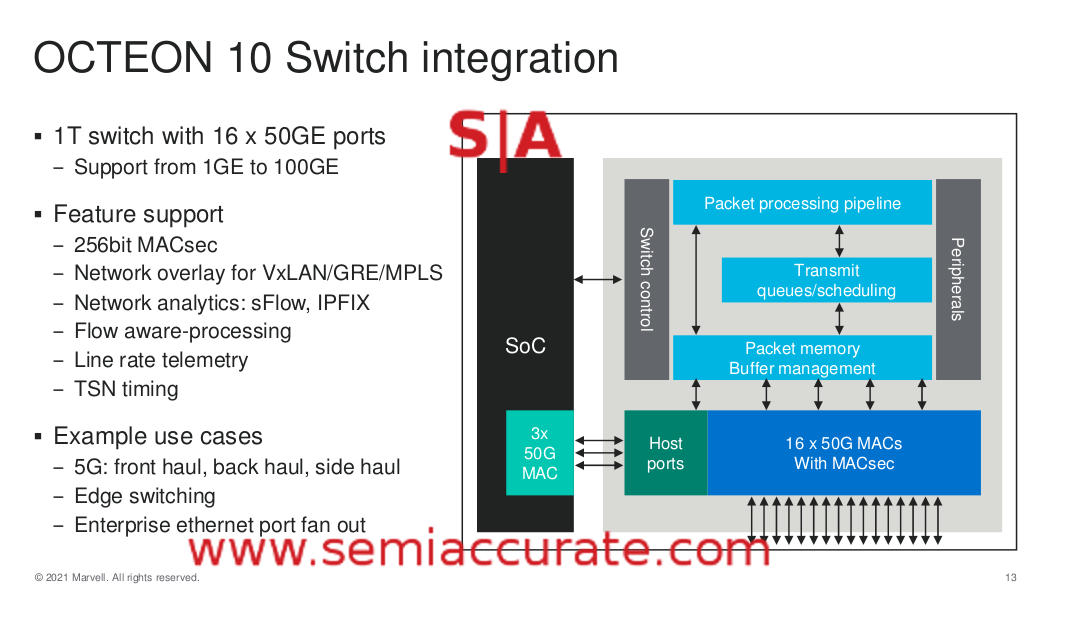
Well this is a switch – Yeah I had to
The last major part of the SoC is the switch and it packs some serious numbers. 16x 50GbE ports meaning up to two 400GbE links or more likely a pair of redundant 400GbE ports for the device. PCIe5 and DDR5 mean that the chip can feed those ports and Marvell claims the accelerators will work at 400+Gbps/line rate so that is about all you need. More important are all the telco features listed above, RANs are the primary market for Octeon 10 and these ports should make that set quite happy.

Meet the (Octeon) family
The Octeon 10 family consists of four devices, each of which will have lot of variants as this category always does. Cores range from 8-24 on the telco oriented CN line and 36 on the datacenter aimed DPU400. If you look at the claimed SpecINT numbers, that is pretty impressive for a 60W device with PCIe5 and 12 DDR5 channels. On the other end, 10W means that the fanless claim earlier is doable if you have good airflow.
Overall the Octeon 10 line is quite impressive. It has all the latest specs from memory to IO and puts the lastest ARM N2 cores on TSMC’s 5nm process. With everything being fed at line rates with low latency, the Octeon 10 is well suited for the needs of 5G. Better yet with the silicon scaling, a customer can run the same software stack from the core to the edge. Octeon 10 seems to hit all the marks for a telco/throughput oriented DPU, SemiAccurate can’t wait to see silicon in action.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026