![]() In the last part of our look at Silvermont we focused on the larger scale advances of this new 22nm Atom core. Now we take a look at the underlying microarchitecture to see what changed there.
In the last part of our look at Silvermont we focused on the larger scale advances of this new 22nm Atom core. Now we take a look at the underlying microarchitecture to see what changed there.
If you recall our earlier article said that just about everything changed, not least of which is going from a single issue in-order hyper-threaded architecture to a dual-issue out-of-order single threaded one. Other than minor changes like these, are there any real advances under the hood? Sarcasm aside, yes there are quite a few of them. Lets take a look in as much detail as we can without earning you a few extra EE credits.
The first detail is the cache sizes, the L1I is still 32K and the L1D is the same 24K as it was in the Saltwell generation, and the L2 is still 512K per core. That is a bit of a misnomer though, Saltwell had 512K for a single threaded core, Silvermont has 1MB shared per two core module. The numbers work out to be the same but it is fundamentally different than it’s predecessor. Intel also shaved two clocks off of the new cache so it is faster as well.
On the ISA side things are equally updated with Silvermont being functionally identical to Westmere. We would tell you what that is in Intel naming schemes, but since they are meant to obfuscate rather than inform, we will just use code names. Short story, SSE4.2, AES-NI with added Intel Secure Key aka random number generator, VT-x2 support, and OS Guard with support for McAfee DeepSAFE technology.
While this security stuff may sound good, Intel has fundamentally botched their security implementations in the past and this time appears to be no exception. Like the larger Core products, if you use them in a public facing manner you preclude any chance you have of being secure because the hardware fundamentally isn’t. Like several other fundamental flaws Intel has in their technology, they also refuse to acknowledge this problem much less address it. On the up side at least you can say it is no more insecure than the Core line.
Back to the good side of things, Silvermont has a complete machine check architecture built-in. You can do real-time instruction tracing now, quite a change from the old Saltwell method of peyote, reading chicken entrails, and diving rods. OK, Saltwell wasn’t that bad but it was 4+ years old, not to mention far simpler in execution by reason of it being in-order. Lets just say that Saltwell brings Atoms into the modern age as far as debugging and problems solving goes and that is a very good thing.
The new OoO Silvermont block diagram, now with added pipes
The first thing to think of when looking at the block diagram above is that the entire core is new, a real clean sheet of paper under the monitor that the CAD work as done one this time. You can see a lot of this in the architecture above and more in the pipeline chart below. The most notable addition here is the lines from the Instruction Queue to the Register Files, mainly because there are now two. As we said in the last article, Silvermont is a dual-issue ‘two pipe’ design, a first as far as Atoms go. That said, one glance at the instruction pipeline makes it eminently clear that there was nothing carried over.
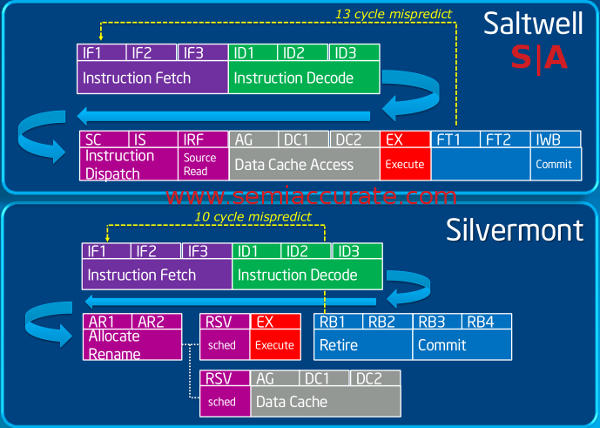
Saltwell and Silvermont instruction pipelines
To start with, Saltwell has a 16 stage pipeline with a 13 stage mispredict penalty while Silvermont has a 14 stage pipe with only 10 cycles of mispredict penalty. Also take note of the alternate pipeline between AR2 and RSV, that one is quite important too. Lets take a look at some of the highlights on this new core architecture.
On the very front end, the branch predictors have been substantially improved for both size and accuracy on indirect branches, plus there are multiple units on Silvermont. The old one wasn’t quite chicken entrails and divining rods but the new one is much better. Going hand in hand with this are the new caches that are much higher bandwidth than before so they can feed the cores better too. There is also a fast path for the cache that allows an instruction that has been previously decoded to skip that work if executed again. Essentially the chip does not have to recalculate the length of the instructions on subsequent passes saving it from one of the larger headaches that face x86 front ends.
From there the core can decode two instructions per clock, a very lucky match up to the two instruction issues per clock. Yes that was sarcasm again. One trick that Intel pulled in this area was to move the loop stream detector from the caches to the queues. This allows the core to power down the blocks earlier in the pipeline sooner and for longer periods. The granularity of what can be clocked down or powered off here is obviously much higher but that is the way things have been moving everywhere, if it isn’t being used during this clock cycle, turn it off to save power. Shutting down decode earlier can be a big win.
One thing that isn’t changed at all from Saltwell is the reorder buffer (ROB), mainly because that core was in-order so it didn’t have one. For the same reason it is all new too and it pushes some interesting bounds. Intel lists two features that it has, late allocation/early reclamation and data-less buffers. Both of them are not something SemiAccurate has seen before, but not to many companies go in to detail about their ROB structures so we can’t claim it is unique.
The late allocation is pretty interesting, instead of taking space for each instruction early on, the ROB doesn’t allocate space until after an instruction has successfully passed through the TLB and is fully twiddled as far as memory spaces go. This allocation is normally done in the AR stage but now can happen a few cycles later. The same happens in early reclamation just the other way around, that slot is freed up much sooner than before for the next entry in line. The net effect is that each entry is fills the allocated slot for a much shorter period of time so a smaller buffer has the performance of a larger one where each entry sits for more clocks. Smaller means less power so compared to a larger traditional buffer of similar performance, you save energy.
Data-less buffers are an interesting solution to power savings too. The buffers don’t store the actual instructions or data, they just hold status bits and point to the correct rename buffers where the data is traditionally also held. Upon retire or commit, that data is moved to the register files as usual and all is good. Like late allocation, data-less buffers allow Intel to make a much smaller cache without losing any performance. This once again saves a lot of power and both tricks allow you to have smaller dies too.
From there it is on to the execution units themselves, and in case this theme wasn’t fully beaten to death, we make sure this equine is indeed deceased. They are all new, completely, totally, and unquestionably new other than three transistors in path that makes the M in PQLMULQDQ. Just kidding, they are all new even that part of the M. From the ISAs supported to the latency of execution everything is a clean sheet design.
Moving back to that branch in the Silvermont pipeline, this is roughly where it comes in to play. If an instruction doesn’t need to access the cache, on Saltwell it had to go through AG, DC1, and DC2. On Silvermont it can skip those stages entirely and just execute if it doesn’t need to hit a cache. Again this saves a lot of time and needless work, and that means better power use too. The only thing that saves power better than turning a unit off quickly is to not use it in the first place.
On the memory pipeline things are once again vastly different than before. Loads can be executed out-of-order, store to load forwarding is massively improved, and there is now support for unaligned 128-bit memory ops. On top of this the TLBs are increased in size, something you would expect to help with the VT instructions Silvermont now supports. Basically the memory pipeline is brought into the modern age as you would expect with the move to OoO.
The execution units on the integer side are all new and the gains show up mostly in the IMUL units. Latency has been mostly halved on these instructions but due to the pipeline changes some instructions have the same net throughput as Saltwell while others are more than three times higher. Other Int instructions are largely unchanged for throughput and latency.
On the FP side the opposite is true. No the multiply instructions did not get slower, they have been left more or less unchanged while the add units get a thorough overhaul. Most of the FP adds have seen their latency almost halved but for the most part throughput was not changed. This means quicker answers but not much more sustained FP add IPC on Silvermont.
Those two are the biggest changes but other instructions have improvements here and there, some substantial some less so. Several classes of instructions have not been changed at all, but for the most part, all of the execution units are completely new. Yup, that horse is now dead, carried away on a clean sheet of paper pilfered from under the screen of the Silvermont designers.
One other point to note on the instruction pipeline side, there is now a full macro-op pipeline. On the older cores macro-ops were cracked somewhere along the way and executed as multiple smaller instructions but Silvermont can deal with them directly. This simplified design and may have lowered power use a bit on the older architecture but the new core does away with all of that work. On Silvermont the macro-ops are passed down the pipe whole and executed as such. The macro-op pipeline is obviously aware of macro-ops and can deal with then whole potentially saving a lot of work in cracking them and executing the multiple resultant instructions. At the very least it will boost latencies quite a bit by only having to run one op through instead of two or more.
Without an EE degree and several phone books worth of NDAs, that is about as deep as we can go in to the microarchitecture of Silvermont. As you can see it is a clean sheet design that fundamentally changes what can be done in an Atom core, how instructions are parsed and executed, and why they are done in that particular fashion. Everything else is modernized too from the process to the ISA, and everything tangential to that. Most importantly Silvermont brings Atoms up to speed with other modern CPU architectures, something you could not say about any of the previous 45 and 32nm iterations of the old core. These long overdue changes are most welcome, now we can’t wait to see what Intel has done to the rest of the SoC.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026