![]() This story is the second portion of SemiAccurate’s look at the XBox One’s architecture as presented at the Hot Chips 25 conference. Part 1 can be found here.
This story is the second portion of SemiAccurate’s look at the XBox One’s architecture as presented at the Hot Chips 25 conference. Part 1 can be found here.
GPU and Video Blocks:
This GPU is not like the others you can buy
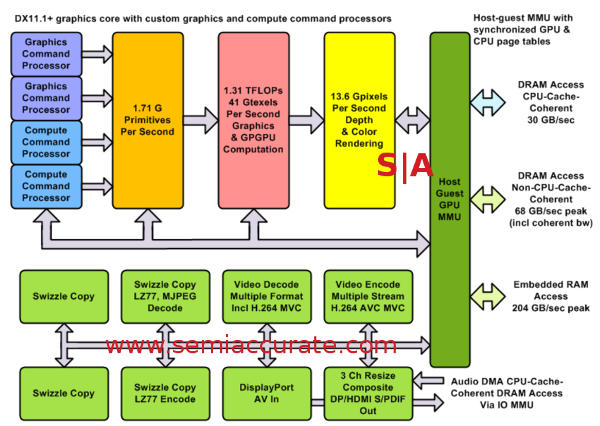
The GPU block is where things start to get really interesting to the point where calling it only GPU is almost a misnomer. Graphics are by far the majority of the transistors here but there are at least seven other blocks in that area. The exact count is a bit nebulous though, Microsoft claims “15 special purpose co-processors” not counting the CPUs and GPUs, eight of which are audio. That would leave seven for the rest of the system and those should end up in the GPU block. SemiAccurate knows that there are several important sub-systems in the XBO that are not on the diagrams or in the talk but we are not sure if the 15 count includes them or not. For simplicity we will use a co-processor count of 7 in the GPU block, 8 in the Audio unit.
Back to the GPU however we can see there is a lot there, the whole block is not just a GPU and media encoder, it is much more. There is obviously the Radeon GPU, something that sources say is somewhere between an HD6000 and HD7000 in capabilities and a fraction behind what Sony has in the PS4. These very minor version differences should be more than made up for by the differences in uncores and system implementation though, don’t read too much in to such minor generational differences. Think of this as more nuance than substantial.
There are two GPU graphics instruction issue blocks and two compute issue blocks on the GOU core proper, something that would not stand out in a similar generation AMD device. It was strongly implied that they have been modified from the basic AMD units but the specifics are not public. It is likely similar to what Sony did with massively beefing up the queue count and depths that are reflected in the changes from the AMD Southern Islands family to the Sea Islands family. Unfortunately Microsoft said absolutely nothing about these changes. The rest of the 3D unit/GPU has minor if any internal changes.
The rest of the units are not well-defined by the presentation but you can get an idea that the video decode and encode engines are substantially beefed up from what AMD puts in their current GPUs. There is no word on whether it is a Microsoft design or the AMD version but the capabilities of always-on recording, encode, and decode presumably without interrupting any DVR functionality points to quite substantial throughput, far more than a PC needs.
With the exception of the Audio Out/Resize/Composting block the other units are plumbing, at least from a users perspective. Game developers may swoon over dual swizzle copy units but for those more interested in the other end of the controller, meh. The Audio Out/Resize/Composting bit however is quite interesting, at least the latter two functions are. Resize does what it sounds, it can resize and scale a video stream on the fly but more importantly is separate from the GPU cores and the video encode/decode blocks.
This says Microsoft is quite serious about video, it will allow for effectively ‘free’ PiP and tiling of video stream limited only by the scaler’s power. While this is doable with the GPU itself it would be intrusive and suck performance from the running tasks. Same with the compositing unit, this is amazingly useful for things like programming overlays, seamless PiP, video conferencing, tasks switching, and most obviously to stuff annoying adds all over your screen until you beg for mercy. Somehow we don’t think the bean counters at MS will care though, but that is just our impression.
In short Microsoft put in some serious hardware to have multiple layers of overlays, scaling of video streams to use with it, and a lot of related hardware to ensure that they can pull off video tricks that are simply not possible to do with modern hardware. The fact that it is separate from the rest of the system also points to the company grasping its uses long before the hardware was started. This is a serious video machine whose power is unlikely to be solely used for the benefit of the consumer without causing any performance degradation on running tasks. It also meshes directly with several of those hidden bits SemiAccurate has heard about. Do not discount this as trivial, it is a fundamental design premise, if not the fundamental design premise of the system, and one that explains the need for dedicated coherent links between the GPU and I/O blocks.
Video Memory Comes in Threes:
If you look at the MMU of the system it has one big, glaring feature, three memory links that all go to different places, do different things at different speeds, and don’t talk directly to each other. The 30GBps coherent DRAM link is essentially another port on the CPU NB and quite unsurprisingly it runs at the same speed for the GPU. This part isn’t odd at all, and if the GPU cores are going to do some compute tasks having a direct and coherent link to the CPU is a must. So far so normal.
Directly below that is a non-coherent 68GBps link to the same DRAM controller but this one doesn’t route through the CPU MMU/NB. Unlike the CPU block it runs at the full bandwidth as the DRAM so as our own Leo Yim figured out, that means 2133MHz. The link is likely to once again be full width and speed, making it 512b wide and half the speed doesn’t buy you much for a simple point to point link like this. Without coherency it isn’t much more than a point-to-point set of wires so why bother being overly fancy?
Embedded Memory Times Four:
Last up is the most widely talked about bit, the links to the embedded memory. It is organized in to four blocks of 8MB each and the bandwidth is listed as 109GBps minimum and 204GBps maximum, and do note it is bi-directional not unidirectional like main memory. This 32MB of embedded memory is not directly contiguous with the main DRAM but the MMUs have the ability to make it appear so in a transparent manner to the programmer. While it is multi-purpose and Microsoft said it was not restricted in any specific manner, there are some tasks like D3D surface creation that default to it. If a coder wants to do something different they are fully able to, why you would want to however is a different question entirely.
As far as arrangements go there are four 256b wide banks for a total of 1024b or 128B wide memory. A little math gets you to a speed of 1.59375GHz, lets call it 1.6GHz because the peak bandwidth is unlikely to be 204.00000GBps. Why is this important? What was that GPU frequency again? 800MHz you say? Think that is half of the memory speed for no real reason? If you said yes you are wrong. With the rumored bump of GPU speeds from 800MHz to 831MHz, this may also bump the internal memory bandwidth up by a non-trivial amount. In any case now you know the clocks.
How that memory is organized and why there are two very different memory bandwidths quoted is also an interesting tale, and one that makes a lot of technical sense. The banks are organized the same way that the main memory is so any striping or interleaving should be replicated in both memory types for reasons of coder sanity not to mention efficiency. It also maps very nicely to the main GPU’s instruction queue count but this could just be coincidence.
The reason for minimum and peak bandwidth counts are quite simple, unlike DRAM the embedded memory doesn’t have to go through all the bank tricks and other bits necessary to get any sane efficiency numbers. It is also much lower latency so any of the write coalescing tricks and other DRAM controller tricks would be pointless and trash the hard-won latency figures. In essence it would be counter-productive to do so. The down side of this is that if the code being run isn’t very good, and by that we mean lots of small (64b) reads or writes, the controller can’t utilize the extra width for anything useful so the bandwidth is wasted. If the running code is well tuned it will do all or at least mostly 256b transfers and possibly hit that 209GBps peak number.
To translate from technical minutia to English, good code = 204GBps, bad code = 109GBps, and reality is somewhere in between. Even if you try there is almost no way to hit the bare minimum or peak numbers. Microsoft sources SemiAccurate talked to say real world code, the early stuff that is out there anyway, is in the 140-150GBps range, about what you would expect. Add some reasonable real-world DDR3 utilization numbers and the total system bandwidth numbers Microsoft threw around at the launch seems quite reasonable. This embedded memory is however not a cache in the traditional PC sense, not even close.S|A
Note: This is Part 2 of a series, Part 1 can be found here.
Updated 9-4-13@10:25am: Changed DRAM to memory in places to clear up some confusion.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026