![]() Qualcomm is talking about their parallel programming API for mobile SoCs called MARE. SemiAccurate saw it in action at Techcon and talked to the company about what MARE is and does.
Qualcomm is talking about their parallel programming API for mobile SoCs called MARE. SemiAccurate saw it in action at Techcon and talked to the company about what MARE is and does.
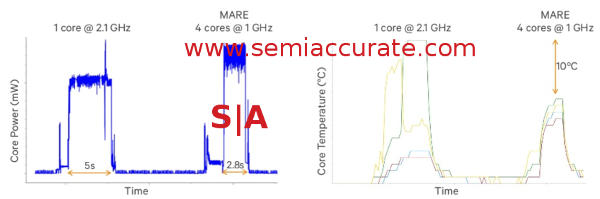
MARE also known as Multicore Asynchronous Runtime Environment is an API and library meant to allow more energy-efficient parallelizable code on mobile platforms. The problem is simple, most SoCs are thermally or energy use bound but also have multiple cores that are either idle or very poorly utilized. Parallel code will help solve both problems by allowing more cores to run more often at a lower frequency. This can save massive amounts of energy if done right. Unfortunately parallelizing code is both very hard to do and some code is just not parallelizable.
How MARE can save power by threading
The idea is simple enough and has been done multiple times by multiple vendors, tag your code with hints for the MARE runtime to parse. If parallel sections are properly tagged, the runtime can push blocks of work to different CPUs, GPUs, or anything else it can run on. The runtime is aware of the hardware state and can intelligently parse the work to the right place.
This is not only useful for HSA type CPU/GPU mixed workloads but also can be useful in big.little style heterogeneous core SoCs. Do note that Qualcomm does not currently have such cores in their lineup but will soon with the 808/810 siblings in a few months. I would consider MARE to be more of a competitor for the big.little global scheduler than the HSA stack that Qualcomm is a part of. At the moment MARE seems to be more of a way to parse tasks or subtasks to homogeneous or heterogeneous cores of the same ISA rather than the more complex HSA style disparate ISAs.
So what does MARE do, or more to the point how does MARE work? First off it schedules work on a per thread basis, not below. Threads in this case are not OS level threads but sub-blocks of code with certain properties, it is more of a task level scheduling scheme. The main unit of work that MARE currently focuses on is a pattern called a pipeline, defined as, “a linear, unidirectional chain of stages (no feedback loops allowed)”. In short think of it as the core of a loop that gets called enough to warrant taking the overhead to parse to multiple cores.
There are many examples of what a pipeline could do, image processing, physics, anti-aliasing, and so on. These pipelines can be internally serial or parallel as long as there are no feedback loops or external dependencies that will screw things up. Since MARE is also a runtime it is aware of the overall hardware state and can dynamically parse the workloads to the right execution unit. At the moment MARE can also dynamically optimize pipelines to a degree, think of it as learning a bit rather than full on JITing.
Pipelines are the main portion of what MARE does at the moment but there are also several other types of what Qualcomm calls patterns. These include pfor_each, pscan, ptransform, and pdivide_and_conquer, the p stands for parallel, the rest is basically the algorithm being used. For the record a pipeline uses a pattern called pipeline, not ppipeline so the semantics are already a bit poff. Qualcomm is actively asking devs to submit generalized application paradigms to be included as a pattern in future updates.
There is nothing magic about MARE, not much automatic on the coding side, and very little self-optimization for the time being. Please note that this API is both a work in progress and early in its life. As time progresses MARE will become more intelligent, more autonomous in pattern detection, and far less manual and programmer action based than it is now. Don’t expect MARE to sit still, these first few iterations picked of some of the low hanging fruit for parallel APIs but there is still a lot more to add that will have significant benefits to the quality of mobile code.
At the moment MARE is sort of open, mainly open to devs but not open as in open source free as in freedom. You can download a copy of the SDK here (Note: Account needed) and the Qualcomm dev site is full of examples, white papers, and all the usual things to bring you up to speed on a new API. Although it currently requires a Qualcomm CPU, the people SemiAccurate talked to at Techcon strongly intoned that it would become a fully open API as it matured, at the moment it is still too early to do so. Once MARE is closer to fully baked, if Qualcomm really opens it up, free as in freedom and free as in beer, it could be a really interesting general use API that does a lot for mobile power use.
The demo Qualcomm was using to show MARE’s benefits was a simple physics demo, the classic ball through stacked blocks multiple collisions. The idea was to both run the graphics calculations in parallel but more importantly the physics and collisions in parallel. It looked like this.

Mare physics demo on an 805 dev tablet
You can see three numbers in the corners, Serial, MARE perf, MARE cruise, along with their frame rates. MARE cruise had almost 10x the frame rate of the other two, we are not sure exactly what perf is but we assume it is just the MARE tagged code with the runtime not parsing parallel tasks. How does MARE achieve such a massive frame rate gain?
There are two parts to it in this case, the first being the obvious parsing of multiple collision calculations to multiple cores for full CPU utilization. If the objects, collisions, and interactions can be pipelined, the rest kind of happens automagically. You might also recall that the A in MARE stands for asynchronous, if you run the physics engine asynchronously, you can decouple it or at least a large amount of the workload from the frame rate. This allows you to do the work you need to do for the simulation and only that, or conversely to not slow frames down when there is no update coming.
At the moment MARE is useful if you are writing things or optimizing them for Qualcomm devices, not a bad call considering their marketshare especially at the high-end. As a general use case it is a bit of a non-starter for the time being but Qualcomm is being realistic and not touting it as a universal panacea. Once it matures and opens, SemiAccurate expects this to change but at the moment the talk around it is quite realistic and sane. How many times can you say that about a company touting a new API? That said, don’t expect MARE to be a short-lived fad, it is here for the long haul for one important reason SemiAccurate dug up.
Note: The following is for professional and student level subscribers.
Disclosures: Charlie Demerjian and Stone Arch Networking Services, Inc. have no consulting relationships, investment relationships, or hold any investment positions with any of the companies mentioned in this report.
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026