![]() PLX, now part of Avago, is finally coming out with their PEX9700 PCIe switching family. If you are thinking this is just another GPU oriented port multiplier, SemiAccurate has news for you.
PLX, now part of Avago, is finally coming out with their PEX9700 PCIe switching family. If you are thinking this is just another GPU oriented port multiplier, SemiAccurate has news for you.
PLX is famous in the enthusiast circles for their 24 and 48-port PCIe2/3 switches that allowed multi-GPU PCIe cards like the AMD R9 295X2 card or anything else X2 for that matter. These switches were also found on various enthusiast motherboards allowing CPUs with <32 PCIe lanes to have two full 16x slots. While they don’t magically multiply bandwidth, it is rare that any GPU would need the full 16 lanes of PCIe3 or anything even close to it so the sharing worked out well.
That is the current state of affairs with the current PEX8700 family of PCIe3 switches, they do just what they purport to, switch PCIe. You can get the PEX8700 family with up to 96 lanes of PCIe3, that is a mere 768Gbps of bandwidth or enough for most users. While these switches are far from dumb, they aren’t much more than switches. All the interesting, or in our case crazy, things you would just love to do with a massively wide PCIe3 switch tends to be hampered by limitations and conflicts on the PC/CPU/firmware side of things. PCIe wasn’t designed as a networking or fabric protocol, it was made to be a host to device interface.
That is where the new Avago/PLX PEX9700 family comes in, it is far more than just a dumb switch. All of the things that you wish you could do via PCIe ports are now likely doable. This is all possible via a bunch of minor sounding but deadly important features PLX added to overcome all the inherent limitations and single system-centric nature of traditional PCIe. Lets take a look at what these new systems bring to the table and how Avago works its magic.
At its most basic level, Avago is looking to replace NICs and storage adapters like Fiberchannel in a PC system using only PCIe. If you think about it, almost all PCs come with PCIe ports and for the last few generations, both AMD and Intel have the ports rooted directly on the CPU die. This means massive bandwidth at really low latencies. Cards like Infiniband and Ethernet are plugged into PCIe ports adding a translation layer, protocol conversions, and all the other little bits that together add up to latency. And cost. If you could just connect two machines via PCIe, everything would be both cheaper and theoretically faster.
The problems start with what PCIe was designed for, a PC connecting to a card, one to one. Worse yet is tends to be master/host to slave/device, two masters lead to a grey area and that is being quite complementary to the resulting mess. PCIe just wasn’t designed to be a networking or multi-master protocol for good reasons. There have been a bunch of additions in recent server CPUs that allow multicasting but that is more or less just for failover. Master to master communications, the thing that you really need to support the Avago/PLX vision, is right out.
So you have to either change the entire PC based PCIe infrastructure or get very clever, and Avago wisely chose the clever path for the 9700. Not only that they did many clever things, not just one. The first of these is called Tunneled Window Connection (TWC) which allows up to 72 hosts to communicate with each other via PCIe essentially turning it into a low latency on CPU die fabric.
The main enabler for TWC is a management processor on the PEX9700 that intercepts an incoming packet and emulates whatever device the server is supposed to talk to. In effect it hides the host status of the other devices and makes them look like a target rather than what it really is. According to PLX, TWC is seamless enough that the host PC, or host PCs, will never know the difference, they are just talking to devices like they always do. It is a nice trick to turn a single purpose connection into a fabric.
Related to this is an embedded DMA engine. Once you have a point to point link like the TWC, with a DMA engine two interconnected PCs can do all sorts of interesting tricks. Given how powerful DMA is, you can effectively stuff arbitrary data into arbitrary memory locations on the other hosts, two PCs connected over PCIe can do almost anything to each other. This has really powerful implications for clustering, failover, and syncing things in general, just DMA to the other side and call it done.
To the user and the software the DMA engine is said to look just like an Ethernet NIC. This is a purposeful emulation which allows the systems connected to a PLX9700 to require only the most minimal if any changes. The system fires off a request to the ‘NIC’ and it should just work. It may not have to go through all the protocol twiddling and overhead, and it may not actually be ‘seeing’ what is behind the switch correctly, but it works. And you don’t have to recode anything, that is a large and clear win.
As an aside I asked PLX about the security implications and they acknowledged the power of DMA in a peer-to-peer setting like this but also pointed out that this was a higher level software problem. While we agree with that assessment, it is something that anyone implementing this technology should be aware of and ask their software/OS/VMM vendors how things are secured. As we said, DMA is very powerful and in the wrong hands, it is still really powerful. That said the potential for good here far outweighs the risks, after all Microsoft has a strong record of publicly proclaiming their security prowess. (Note: SemiAccurate feels the company has an unsecurable OS on purpose and doesn’t actually want to secure their software because they make too much money off insecurity).
Although TWC doesn’t play much of a role in the next bit, the command processor and likely the DMA engine do. Together they add up to shared I/O, in other words one device used by two or more hosts. You can probably guess how this works out if you can make a host look like an endpoint and connect multiple hosts without them stepping on each other. If you can emulate nearly anything without stepping on the toes of one bit or another, sharing a device is the easy bit.
Even if it isn’t the most technically complex part of the PEX9700, device sharing is probably one of the most important. The most important aspect of this is going to be failover/hot sparing of server for VM heavy workloads. For that category, shared I/O is a match made in heaven. No more headaches trying to hide what is really going on from the system, no more hacked firmware, and no more non-standard tricks. Sure there will be a lot of coding on the OS and application side to make sure the failover works in software, but the heavy lifting is already done in hardware.
In essence all of this pulls the I/O device closer to the server. You can tunnel, DMA, and share devices so it all looks like a DAS system when you are really closer to a SAN. Better yet you go from CPU directly to the PEX9700, then directly to the device or storage, that lops off at least two hops, two protocol translations, and a lot of time. It all works very much like SRIOV from a single system perspective and MRIOV from the big picture side. (Note 2: We know MRIOV is pretty much dead and no one really implemented it but PEX9700 I/O sharing does much the same thing while looking like SRIOV to each host.)
The next most important bit is called Downstream Port Containment(DPC) and it is small but deadly important. If you have ever had a PCIe device fail or crash, you know what happens, the system locks. On Windows it almost assuredly means a blue screen unless the system locks before it gets that far. More reliable OSes may have a small chance of handling a PCIe request failure with a bit more grace, but usually they go down spectacularly too.
If you have multiple hosts connected to the same device and it has a bad day at the office, you just have multiple hosts go down. Some protocols like SAS which are meant to have many devices on each card have measures in place to prevent this. With dozens of HDDs per card, if SAS didn’t have a failover protocol in place, a system would have uptimes measured like, “Do you have a nine?” vs how many nines.
DPC is like SAS failover but for PCIe. If a command is sent and doesn’t come back in time, the old way was for the host to retry it a few times, then die a horrible death. With a PEX9700 in place, if a command doesn’t come back in time, it can emulate the device ala TWC and send back an error message rather than an infinite wait. A system may need updated drivers or firmware to be able to handle this failure message, but it won’t actually go down in flames or just hard lock. If you have two shared devices connected to a PEX9700, it can failover to the second without the overhead and expense of full mirroring. DPC enables a lot of interesting system configurations that are just starting to be explored.

PCIe based failover, sharing, syncing or… all three?
If you put it all together you can make some very interesting system configurations like the one above. Two shared PCIe/NVMe SSDs per system and each system sharing its entire I/O subsystem with a second system. From here you can get really creative and do things that, well, you previously weren’t able to do without tons of specialized hardware and software. You can save a lot of money by not having to have a redundant host in case a first locks up due to a PCIe request failure and/or you can share your devices across multiple hosts to save data duplication costs. There are tradeoffs to each method of course but it very likely will end up much cheaper, faster, and more efficient than the ‘old way’. If you look at the old vs new topologies, the savings and extra potential are pretty obvious.
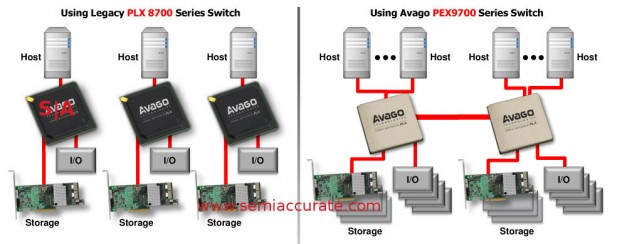
The old was is 1000 less than the new way
The Avago/PLX PEX9700 family being released today is a true family with seven members all called PEX97xx with the xx being the PCIe3 lane count. There are two groups of parts, one with a management port and one without. The 9712 and 9716 are the ones without management ports, the 9733, 9749, 9765, 9781, and 9797 have the port. In case you missed the implication, the PEX9797 is capable of 96 full PCIe lanes plus one for management. Even with this massive lane count, latency is a mere 150ns for devices with a management port and a worst case of 158ns for the PEX9712 without one. There is one port per four PCIe3 lanes, add one for models with a management port too for a total of 25 on the PEX9797.
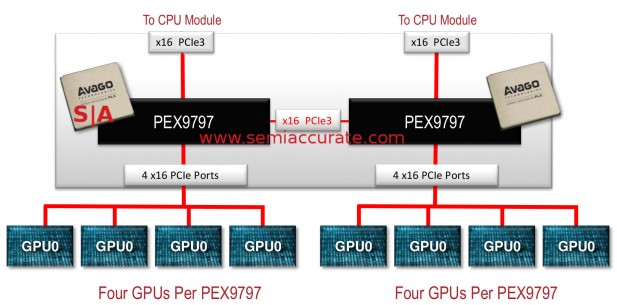
Need more GPUs? Here is your answer.
That of course allows you to do crazy things like a PC with four GPUs sharing full bandwidth to a hot spare machine with four other GPUs, all without external hardware. If your box can play Crysis, it can play Crisis with four-way Crossfire and full hot failover as long as you can swap keyboards in time. OK, this is not a sane gamer configuration but it is quite useful for number crunching, analysis, and HPC.
Avago says that the last generation PEX8700 family was used about 55% for storage applications, 25-30% for servers, and the rest for communications apps like control to dataplane messaging. The new capabilities brought on by the PEX9700 line is sure to skew that mix quite a bit because many of the items on a system topology architect’s wish list just went from impossible to possible. Better yet if a mere 24+1 ports and 96+1 lanes are not enough for you, you can chain up to three of the PEX9700s for a total of 72 ports but it adds a bit of latency for each hop. You can chain more but at that point it becomes potentially blocking so it will work but not nearly as seamlessly as <72 ports.
One nice bit about the PEX9700 is the scalability. As you can see from the ports vs lanes counts, the PEX9700 is balanced for a PCIe3 4x per port configuration but it is quite flexible. You can have 1x, 4x, 8x, and 16x lanes per port for a total of 128Gbps of bi-directional bandwidth. Avago is quick to point out that if you are doing something like a converged Ethernet solution for VMs and you need to move from 1GbE to 10GbE or 10GbE to 40GbE, you are looking at an expensive NIC and switch upgrade.
With a PCIe based fabric you can just add lanes, sure you could possibly need a few more standard SPF+ cables, 5m for copper, km for fiber, but that isn’t a major expense. For that matter the whole PEX9700 based network infrastructure is not a major expense either. On the PC/server-side the PCIe lanes are already there because they are a part of your CPU, as are the slots. All you really need is a $20 paddle card that potentially boosts and conditions the signal a little, effectively a PCIe -> SPF+ dongle.
If you use a PEX9700 as a top of rack switch, each lane out goes directly into a PCIe card, the ‘system’ housing the devices is nothing more than a PSU and a physical cage. It isn’t expensive, especially compared to a 10GbE switch and lets not talk about 40/100GbE infrastructure. Sure a PEX9700 setup as a ToR switch means you are limited to a mere 72 ports, minus a few for interconnects, but you can still probably beat 48 ports and still have a few to spare. This new line from Avago really does turn PCIe into a fabric.
You might recall the management ports mentioned earlier, they are quite important. If you are using a few PEX9700s as a replacement for a ToR Ethernet switch, you need to be able to manage it remotely. That is what the management port is for, and since it is a direct PCIe out, you just plug an Ethernet or KVM device into it and call it good. Avago also has logic in the PEX9700 line to allow system designers to chain and combine management ports through other switches. In short the management port isn’t a hack job added on, it has a lot of bells and whistles.
Avago/PLX has had PEX9700 silicon in the labs since last August and they work just fine. The PEX9700 line is built on an unspecified 40nm process, likely TSMC, and pulls around 20W. If you think about that compared to the pull of an Ethernet switch, three 9797s, a few bits of control hardware, signal amplification, and signal conditioning, it just sips power. Power in the data center is cost, latency is pain, and every added card is a failure point.
That is why the Avago/PLX PEX9700 line is so interesting. It breaks may of the old architectural barriers with a solution that is potentially much cheaper, vastly lower latency, and quite flexible. You can do things with PCIe fabrics that you just could not do before, and it all comes down to clever hardware tricks in the switch chips. Those tricks mean little or no code or modifications to the PC hardware to get the desired and previously impossible results. Cheaper, faster, more scalable, and potentially much more reliable, how can you lose? And you can play Crysis with more nines when the boss isn’t around, win/win.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026