![]() Just under a year ago, AMD announced Boltzmann, today they are on the 4th update to ROCm. In case you don’t get the connection, allow SemiAccurate to point out that the Boltzmann Initiative for HPC is now called ROCm.
Just under a year ago, AMD announced Boltzmann, today they are on the 4th update to ROCm. In case you don’t get the connection, allow SemiAccurate to point out that the Boltzmann Initiative for HPC is now called ROCm.
Your first question is probably answered by Radeon Open Compute platforM, because ROCp does not roll off the tongue nicely. Your second question is probably answered with ROCm is an open source platform for HPC work, compilation, runtimes, and just about everything from the hardware to the what the code runs on. AMD hopes it will be the, no _THE_, platform to run heterogeneous HPC code on.
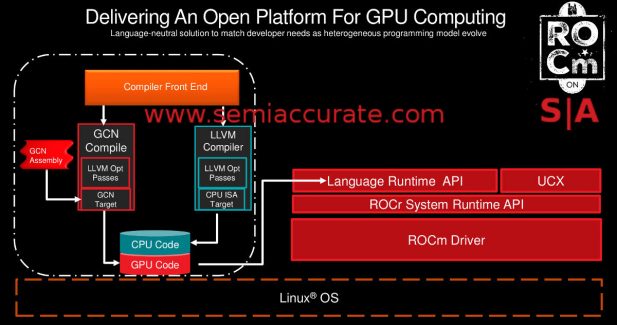
AMD’s ROCm overview
AMD lists four things that comprise ROCm, a headless Linux driver for GCN (graphics 8 and up really) devices, HSA, compilers for multiple languages, and lots of open source tools and libraries. We won’t go into HSA in detail like hQ and the HSA v1.1 update, search the site if you want more. Lets just say it covers the hardware essentials on AMD, ARM, and many other CPUs and SoCs.
On the driver side there are a few big updates too, starting with the headless bit for the Linux drivers. HPC and GPU compute accelerator users don’t need direct video outs all that often, the cable from the cloud farm to your desktop is a bit lossy after the first 5km or so. Joking aside, the first big change is that AMD GPUs now allow the full memory set to be used per task, or at least all but 250Mb or so. This is a huge change from the past and for competing architectures where 2GB or 4GB were hard limits. Now you can have up to 31.75GB per process, more in future cards.
Better yet if one card isn’t enough, the current ROCm versions, 1.2 as of yesterday, adds peer-to-peer multi-GPU support and peer-to-peer RDMA. If you are into GPU based HPC work, this is a big deal, you can effectively cut the CPU out of the picture and save a lot of latency for your project. There is also a new set of system APIs and tools to keep control of it all, some related to multi-GPU, some not.
Then we have the compilers which target the ROC Runtime or ROCr, not ROCe as the precedent might suggest. There are two parts here, HCC and HIP or heterogeneous Compute Compiler and Heterogeneous-Compute Interface for Portability (Yes we think HIP is a better acronym than HCIFP too). HCC targets both the CPU and GPU with one compiler and is built on CLANG/LLVM and libC++. It supports OpenMP3.1 and OpenMP4.5 for GPU offloading as well. Other accelerators can be added too.
HIP is based on a C++ kernel with a C runtime as well. There are tools to suck in CUDA code and others, plus the resultant output can be run on both sets of GPUs.. For this you need to run the HIPified code through HCC and NVCC but that isn’t a high bar. AMD is aiming to make a universal HPC compiler framework and runtime, and they seem to be getting close.

Can you spot our little funny?
Last up is the tools and languages and there are a lot, so many that I will just show you this picture above. On top of this ROCm will have support for the OpenUCX framework, that should bring in lots more code in the near future. If you are getting the idea that AMD is trying to lay groundwork for open and compatible HPC code in a heterogeneous environment, you have the idea.
While this brings us up to speed on the current state of ROCm, today sees the release of v1.3, the fourth major update this year. It adds the Hawaii support, mainly for older cards with big memory footprints, the Polaris family, and two Linux variants, Ubuntu 16.04 and Fedora 24. ROCm itself now supports GPU concurrency, KVM pass through, images for ROCr, DKMS loadable modules for kernel services, more KFD signals, and doorbells for GPUVMs.
The compiler side is also updated with LLVM 4.0 for native GCN compilation, HCC CLANG 4.0, and HIP hits 1.0. For tools there is now a ROCm profiler plus a lot of new power heuristics. This is important because it takes the Powertune and related algorithms aimed at peaky gaming loads and re-tunes them for sustained HPC workloads. There are also new versions of rocBLAS, rocFFT, Tensile, and ATMI. Best of all, OpenCL is now officially supported on ROCm, v2.0 with a 1.2+ runtime. This will have an official preview on December 14, it won’t be there right away.

Two of these things were NOT expected
Then we get to the interesting stuff, the new hardware support. You will notice on the slide above that Intel Haswell and Braodwell CPUs are supported, plus AMD’s upcoming ZEN devices. That is interesting but the next two, Cavium’s ThunderX and IBMs Power 8 are a bit unexpected. Consider me floored by this diverse architectural support, x86, ARM, and Power? Then there is GenZ, CCIX, and OpenCAPI for the odd user who may need to connect their systems to something too.
The last bit is something quite in-vogue for HPC and AI work, lets just say large subsets of the heterogeneous compute marketplace in general, native 16-bit support. ROCm now supports Float16 and Int16 natively on Fiji and Polaris GPUs, no more conversion. This simplifies code, speeds up runtimes, saves power, etc etc. You get the point, they are there, supported natively in hardware, and now ROCm supports them as well. HPC people will either not care or jump for joy, there isn’t much in between, you need native 16-bit or you don’t.
When AMD opened up their ISA and software a year ago with Radeon Open Compute, we all wondered if it was real or would be forgotten about in a few months. There have been four solid releases of ROCm since then, languages added, tools, libraries, different ISA hardware, and lots more since that day. If you want a real eye opener, look at the core platform contributors, you will see universities, fruit-themed hardware, and lots more. You will even find the fully documented Fiji ISA manual. I guess ROCm is quite alive.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026