![]() Today Broadcom is updating their StrataDNX line with newer, smaller, lower capacity chips! It took SemiAccurate a bit to wrap their heads around this unusual turn but it all makes sense.
Today Broadcom is updating their StrataDNX line with newer, smaller, lower capacity chips! It took SemiAccurate a bit to wrap their heads around this unusual turn but it all makes sense.
The head scratching began when we got the briefing slides from Broadcom on the three new StrataDNX chips. We sent an email to our PR contact asking if the speeds were a typo because the 2015 parts, Jericho/BCM88670 and QumranMX/BCM88370 sported 800Gbps capacity per chip, the new ones for 2016 topped out at 300Gbps. Was there a typo in the stats for the Kalia/BCM88476 and QumranAX/88470, newer generations are always faster right? One look at the 120Gbps number for the QumranUX/BCM88270 should have told us no but we asked anyway.

Where the StrataDNX lives
Short answer, no, those numbers are right, the new chips are smaller and lower capacity because as you can see above they serve a different part of the market. 2015 saw the release of the biggest members of the family, these new ones are filling out the smaller and lower capacity chunks. Lets start out by telling you about what the family does, they are aimed at line cards, telco switches, service providers, and markets not covered by the datacenter oriented StrataXGS/Tomahawk 2 line.
Starting with the big 2015 line, they are very similar beasts with the aforementioned 800Gbps forwarding capacity with port interfaces from 1-100GbE. As you might expect from this line of devices it has a packet processor that has “optimized packet engines” rather than a full network processor. This makes it field upgradeable, new features can be added and there is a bit of flexibility within the constraints of the dedicated hardware blocks available. It is obviously far less flexible than a full NPU like Netronome chip but the StrataDNX method is more power efficient. Think of it as a middle ground between dedicated hardware and full software implementations, but more to the dedicated side than an NPU.
Broadcom is keen to point out that the DNX line has deterministic performance at full line rates, you may add latency with more features but it shouldn’t affect throughput. Part of this is from the Hierarchical Traffic Manager, part from the architecture of the system, it was designed from the ground up to be used by telcos and service providers who value deterministic performance much more than standard network switches.
Both the Jericho and QumranMX support external DDR4/GDDR5 memory expansion, external table expansion via KBP (external Knowledge-Based Processor from Broadcomm), and an FPGA interface for statistics gathering and management. Since Broadcom doesn’t make switches and line cards, only silicon for them, the use of these features, the software that goes on them, and the board designs are all value added bits for customer OEMs to use as they see fit.
Things get interesting when you look at the difference between the Jericho and the QumranMX, it boils down to the uplink. QumranMX is meant for standalone devices, think big pizza boxes and the like while Jericho is described as a line card on a chip. The name line card implies backplane and you would be right if you are thinking this necessitates another chip to control it. That backplane is powered by the last of the 2015 family, the FE3600/BCM88770, a device with no cute Dune reference in the name.
The FE3600 is a much simpler switch with 144 25Gbps interfaces which can support 100Tbps in a single plane. If you are wondering how this works without multi-tiering, it is a bit complex to put into words and far more complex to put into diagrams that don’t need a microscope. Each Jericho can have up to 36 25Gbps links to the FE3600 so the full bandwidth and more is always available.
If you line up FE3600s each connecting to 36 line cards with a Jericho per, you have a single plane with all that bandwidth, and yes it is full bandwidth to each card from each card even if the stream can get split up into 36 pieces before being recombined. The DNX line has its own internal protocols for a reason, if you try doing these tricks with standard packet protocols, well don’t blame us for the results. We doubt anyone will actually build a device that maxes these counts out, but it can be done. Most workloads would be adequately served by much smaller octopi.
Now that you have an idea about what the big StrataDNX chips do, what about the three smaller ones introduced today? This trio, Kalia, QumranAX, and QumranUX to refresh your memory, are smaller versions of the two existing chips. The first two are 300Gbps devices, the last is ‘only’ 120Gbps, and like the earlier chips, Kalia can connect to an FE3600 and the Qumran pair can’t. If you need a smaller line card on a chip, think Kalia, smaller pizza box is the right fit for QumranAX, and a person pan router gets a QumranDX. To use a less technical comparison, daddy Qumran = MX, mommy = AX, baby = UX, and the marriage of Jericho and Kalia hasn’t produced a baby yet.
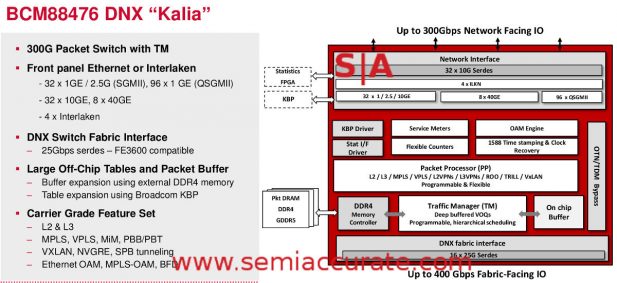
Kalia block diagram
Kalia and AX are pretty much the same as their larger brethren, no real features missing but some things like buffers scaled down for the lower workloads of the new chips. One good example of this is Kalia only has 16 25Gbps uplink ports to connect to a FE3600s with but you can still link up the two plus mix and match with Jerichos where appropriate. QumranUX is scaled down further from the AX and also lacks the interface for the external packet processor (KBP). The new three are not directly binary compatible with the older pair but are API compatible. Think recompile plus a few tweaks to address the smaller port counts, buffers, and the rest.
The idea for the entire StrataDNX line is simple enough, start with the big telco/provider level switches and push the same architecture out to the remote nodes and even edge devices. By edge devices we mean RANs and large cell towers, not home routers and picocells. The markets Broadcom is aiming this line at values consistency in coding, management, and performance so a top to bottom device line is pretty much a must have for salespeople to get returned calls.
So that is why Broadcom launched the smaller Kalia, QumranAX, and QumranUX trio today, to round out their lines. You have Jericho and Kalia as line cards connected to the fabric of FE3600 through copper filled sandworm holes or something like that, at least that sounds better than an organic PCB to us. For standalone devices, pick your flavor of Qumran, MX for 800Gbps throughput boxes, AX for 300, and UX for 120, It all makes sense until you try to trace the dataflows in a fully connected 100Tbps Jericho+FE3600 system, then your head hurts.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026