![]() Marvell is launching two new CPU lines today, the Octeon TX2 and the closely related Octeon Fusion family of devices. You may be familiar with these SoCs from the old Cavium lines SemiAccurate told you about earlier.
Marvell is launching two new CPU lines today, the Octeon TX2 and the closely related Octeon Fusion family of devices. You may be familiar with these SoCs from the old Cavium lines SemiAccurate told you about earlier.
The basis for both of these families is the Octeon TX2, the successor to the Octeon TX which was itself a MIPS based SoC with it’s cores replaced by custom ARM cores. These are not heavy compute oriented devices like an Epyc or Xeon, that is the realm of Marvell’s Thunder TX line. Instead the Octeon TX2s have just enough CPU power to support their massive packet, crypto, and related engines for high throughput with low latency.
If you take an Octeon TX2, add more PHYs and baseband capabilities, you get an Octeon Fusion. Currently there are several lines of Octeon Fusions that are aimed at everything from macro-cells to pico-cells. This new SoC today doesn’t add a suffix with one higher number than the 2015 variants but the model numbers move from CNF75xx to CNF95xx so there shouldn’t be much confusion in the marketplace. Lets take a look at these new offerings in more detail.

Marvell’s Octeon TX/TX2 lineup
The TX2 line has four members, the CN913x, CN92xx, CN96xx, and CN98xx which range from 4-36 cores. If you notice in the diagram, the CN913x uses different cores from the other three, an A72 instead of a custom Marvell ARM v8.2 core. The A72s are arranged in a cluster of four, the Marvell cores come in clusters of six, a number which is said to be better matched to the throughput of the engines more than any specific interconnect topology. That means the CN92xx has 3 clusters, CN96xx four, and the CN98xx has 6.
The Marvell cores seem to be a significant upgrade from the older Octeon TX cores as well. They are now fully out of order, quad issue, and have three levels of cache. Supporting the ARM v8.2 ISA also puts them right up there with the best modern devices that are on the market now so this should bring a serious performance improvement over the older TX line.
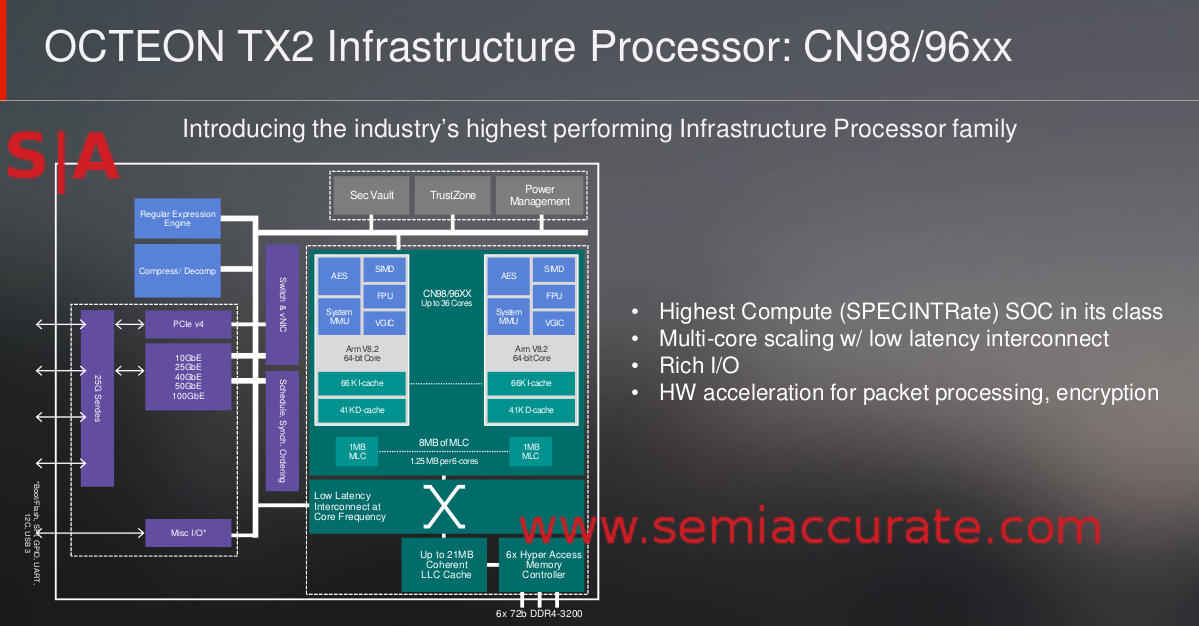
Block diagram for the CN96/98xx SoCs
Looking at the block diagram of the Octeon TX2, it is pretty similar to the older Octeon TX but just about everything is updated to a newer spec even if the fundamental layout is essentially the same. The most important changes are that the SERDES are now 25Gbps so 100Gb Ethernet is now supported and PCIe is Gen4 instead of Gen3. CPU frequency went up from 2.2GHz to 2.4GHz, DDR4 clocks went up as did channel counts, and just about everything else is ‘more’.
Core counts do go up too from the 24 in the CN83xx to 36 in the CN98xx, and that is on top of their architectural upgrades. The CN98xx has 4x the throughput of the CN83xx but only 50% more cores. That ratio should give you a good idea of the improvements to the cores themselves, these are not the simple devices of the first gen Cavium/Marvell parts anymore.

The TX2 lineup with one TX for comparison
In the end this buys you support for newer standards which bring both higher bandwidth requirements and more complex operations. The largest chip, CN98xx, can support up to 5x 100Gbps Ethernet with 200Gpbs of IPSEC and a little more IP forwarding capabilities. If you think about it, two 100Gbps in and two 100Gbps out would need about 200Gbps of IPSEC and IP forwarding. The cores can do a bit of packet twiddling on top of it meaning the Octeon TX2s can suck in data, manipulate it, and spit it out at line rates with very little latency.
That is the point of the line so on paper it looks like the new TX2s have all they need to do this at the magical ‘line rate’. If you look at the specs of the older CN83xx in the second column, 10Gbps was the max Ethernet speed supported there and the specs for crypto and packet twiddling point toward it being in the same ‘line rate’ ballpark as the I/O throughput too, amazing how that works out.

Marvell Octeon 913x SoC block diagram
If you look at the smallest variant of the Octeon TX2 line you have the CN913x which looks very different from the larger three variants. It is a fusion, but not an Octeon Fusion, of standard ARM cores and the Octeon TX/TX2s. Since it is meant for smaller cells and devices, there really isn’t a need for 25/100Gbps Ethernet or the heavy packet throughput and crypto of the larger TX2s.
Basing it on standard components makes a lot of sense, there is only so far you can scale down the big chips, after a certain point the interconnects and ancillary bits eat up more die than they are worth. Pulling off selected accelerators and placing them on a device much better suited to this market segment makes a lot of sense to SemiAccurate. The end result is a cheaper device that still does the needed work and more importantly is still capable of running the same software as the bigger TX2s so it is a win/win for Marvell and customers.
If you want to build a 5G macro base station you can take a few TX2s, slap a bunch of baseband chips in front, throw in a few FPGAs, add a little more support silicon, or just go the full ASIC route. If you don’t like pain and needless work, you might want to consider the new Octeon Fusion line. Imagine a lower end TX2 with all the PHYs and protocol engines, baseband capabilities, and DSPs you need already on board. It looks like this.
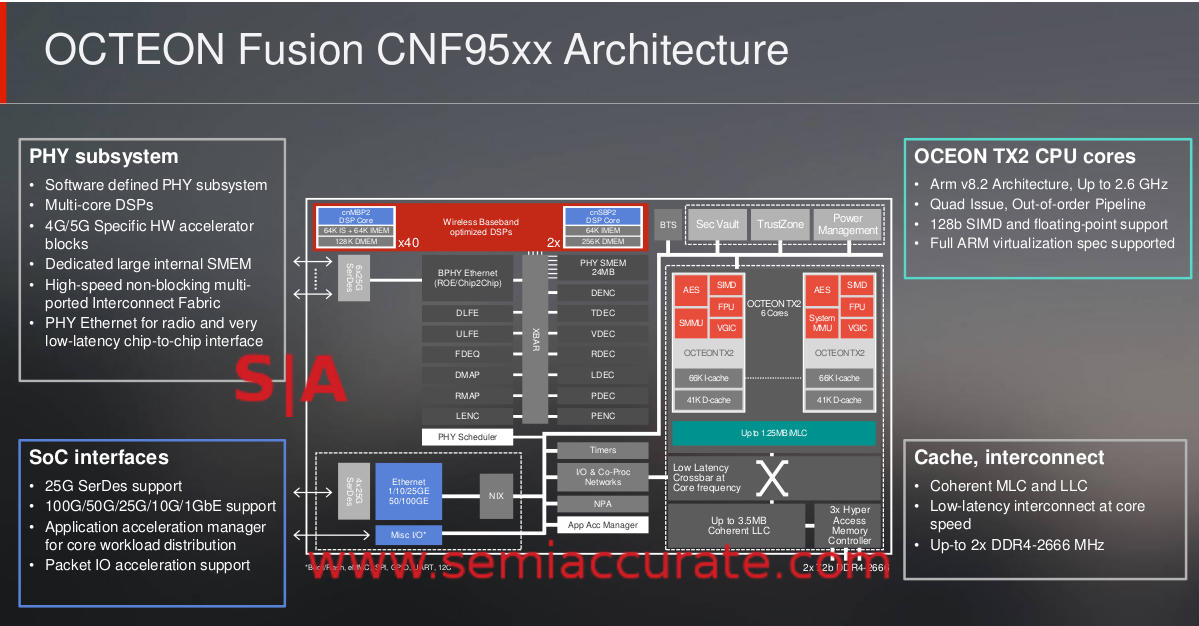
Marvell Octeon Fusion CNF95xx SoC block diagram
One of the most interesting changes from the older CNF75xx line of Octeon Fusions to the new CNF95xx is the targeted OSI layers. The older parts would do most of the stack while the newer chips are only aimed at layer 1 parsing. This allows them to focus on doing the most time critical tasks fast and handing them rest off to a central location stacked with TX2s or whatever else the telco chooses to deploy. It also shines a light on the evolution of the current state of thinking in CRANs or distributed base stations. For those wondering where the split would end up, this is a pretty solid piece of evidence that it will be between layers 1 and 2.
At first glance the CNF95xx may look a lot smaller than the CN92xx because it has one cluster of six cores and two memory channels but packs more I/O and keeps 100Gbps Ethernet support. On top of that the majority of the die is taken up with the PHY subsystem. It’s DSPs and their associated memory, there are 40x blocks with 256KB of various memories and two with 320KB, plus the rest of the programmable packet engines make this a really large block.
From an overarching point of view the Octeon TX2 is more or less a TX with updates to every basic block while the Fusion 95xx is more of a refocusing of the 75xx line. The hard split between Layer 1 and Layer 2+ processing allows the 95xx to focus on fewer operations and do them faster with lower latency. If you look at how much lower the latency requirements for a 5G packet are vs a 4G packet, these changes make a lot of sense, it is really hard to do it any other way.
If you are using 5G in the west, there is a high likelihood that you are using a CNF95xx. Marvell says that they have been in production and deployed from a “Tier 1 OEM” since early-2019. Based on conversations at MWC2019, SemiAccurate thinks this is Samsung. In any case Octeon Fusion CNF95xx SoCs have been deployed in the wild for almost a year and the second generation parts with customer specific additions are imminent.

You put them all together and get….
To wrap it all up we will show you this diagram of a ‘hypothetical’ 5G macro cell base station design. You take one CNF95xx and couple it with a CN92xx, add in a few radios, and off you go. Both SoCs use very similar APIs so the software side is simplified, plus the TX2s scale up to much higher core and I/O counts should you want to implement a CRAN/distributed setup. And if you are wondering why the phrase hypothetical was in quotes, both of those parts are shipping now and have been for a while, the competition has not so…S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026