![]() Today ARM released two new GPU cores, the Mali-G78 and the Mali-G68. The later of these is a new tier of device and SemiAccurate found a lot of interesting bits in this new architecture.
Today ARM released two new GPU cores, the Mali-G78 and the Mali-G68. The later of these is a new tier of device and SemiAccurate found a lot of interesting bits in this new architecture.
The Mali-G78 GPU is the second iteration of the Valhall architecture with the G77 being the first. Before that we had the Bifrost architecture found on G76 and G72 cores with more units per execution engine but narrower warps. Like the G77 the G78 has a 16-wide warp and the same overarching structure but the max shader count increases from 16 to 24 in G78. Each of these shaders carries an execution engine that processes two warps per cycle. It looks like this from a high level.

Yup, looks like a Valhall GPU
If you are thinking that the G78 doesn’t do much to improve on the G77 other than to add 50% more shaders, you would be way off. There are two big new features, Asynchronous Top Level and Fragment Dependency Tracking, that grab the headlines but a lot of the gains come from detail improvements in efficiency and performance. ARM is claiming 10% better energy efficiency, 15% better performance per unit area, and 15% better performance in machine learning on the same process under similar conditions. This is claimed to translate into about 25% higher performance when comparing a 2020 device to a 2021 device.

Enter the marketing slide
Lets look at the high level additions first starting with Asynchronous Top Level (ATL). As the name suggests, ARM took the Mali-G78 and split it in to two clock and voltage domains, one for the shaders and one for the rest of it, aka the Top Level. The idea is pretty simple, some workloads are dominated by heavy number crunching on the shaders, others by setup or memory waits. If the workload has lots of triangles it will stress the top level more than the shaders, low geometry but high frame rate games can do the opposite.
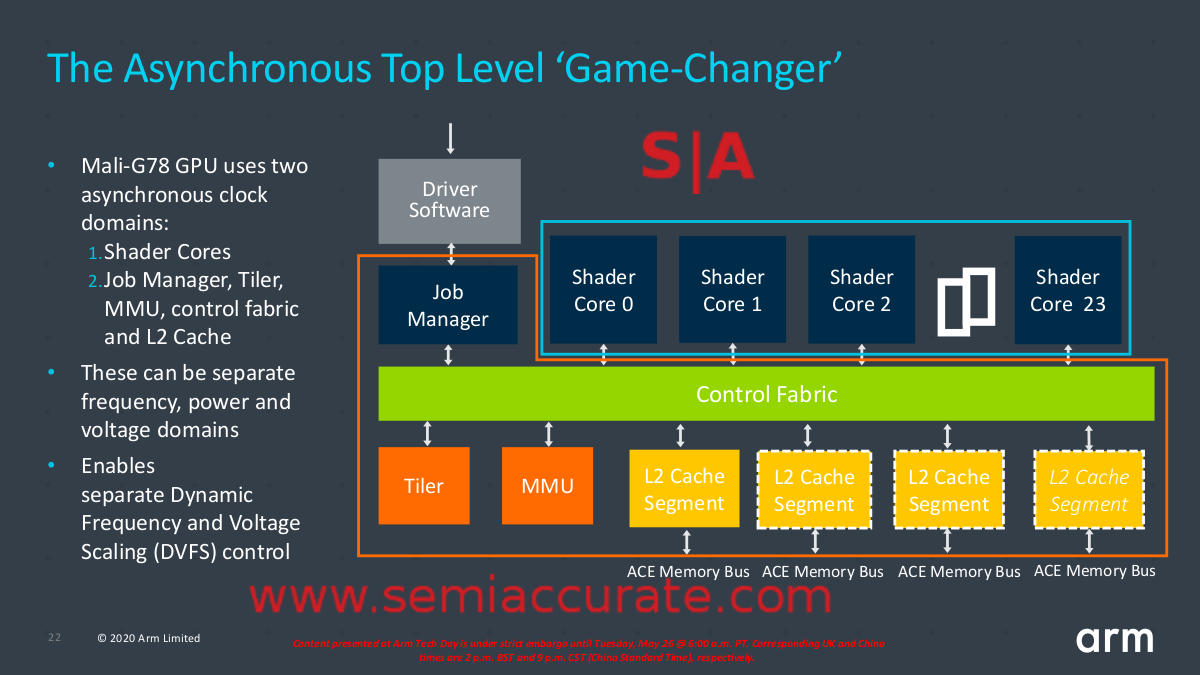
Top Level is actually on the bottom here
The idea behind ATL is to optimize for differing workloads, you can clock the top level up to >2x that of the shader cores, the exact amount is an implementation choice by the ARM licensee, so the cores can be fully fed all the time. If the game is simple, you can clock down the top level and keep the shaders spinning at full rate. ARM also points out that memory bound workloads like object detection will give the shaders nearly no work for long periods so they can be clocked down while the top level waits on data.
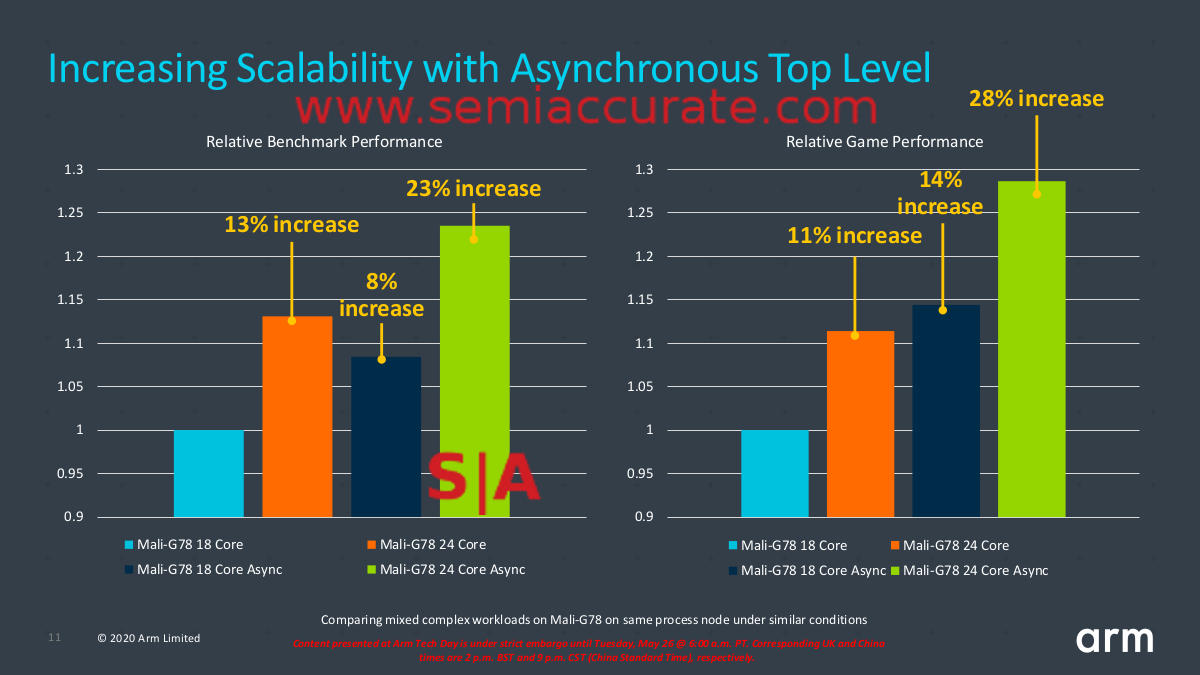
The gains are pretty substantial
ATL isn’t a grand leap of understanding, it does the obvious thing and allows the two major units of a Mali-G78 to run at the optimal rate under a wider array of workloads than in G77 and older GPUs. ARM said the area gain from an ATL implementation was pretty small and the added clocks do burn more power but that is minuscule compared to having the shaders clocked high while idling. In short ATL is a win/win as you can see from the numbers below. Better yet the overall net power savings from ATL is between 6-13%, a very impressive number given how much of a device’s energy is consumed by the GPU.
The other big bang feature is Fragment Dependency Tracking (FDT), and it is a big win in a lot of games. That said these games, complex modern 3D ones with an exploding triangle count and added shaders, will only become more common in the coming years so expect the benefits of FDT to become more prominent too.
![]()
Fragments do add up
So how does it work? There are two main ways, the first is to lower the granularity of fragment discard from 16 to 4 threads. This adds a little work up front but saves quite a bit of unneeded work and avoidable waits later on so it is a clear win in heavy geometry workloads. FDT also updates dependencies quicker in hardware when they are found, so again less work and waits. Basically this new method checks things more often and does the work faster when dependencies are found. While the G77 could do both of these things, the G78 does them at different intervals, think of it as rebalancing to better suit a changing software landscape.
With those big bangs out of the way, lets look at the details starting with a big one for energy efficiency, the FMA unit. ARM claims that 19% of the GPU’s dynamic energy on the G77 is consumed by the FMA unit alone, not surprising if you consider how much of any 3D scene is rendered using that type of math. This new unit which was co-developed with the CPU FP-ALU team cuts out about 30% of that energy use.
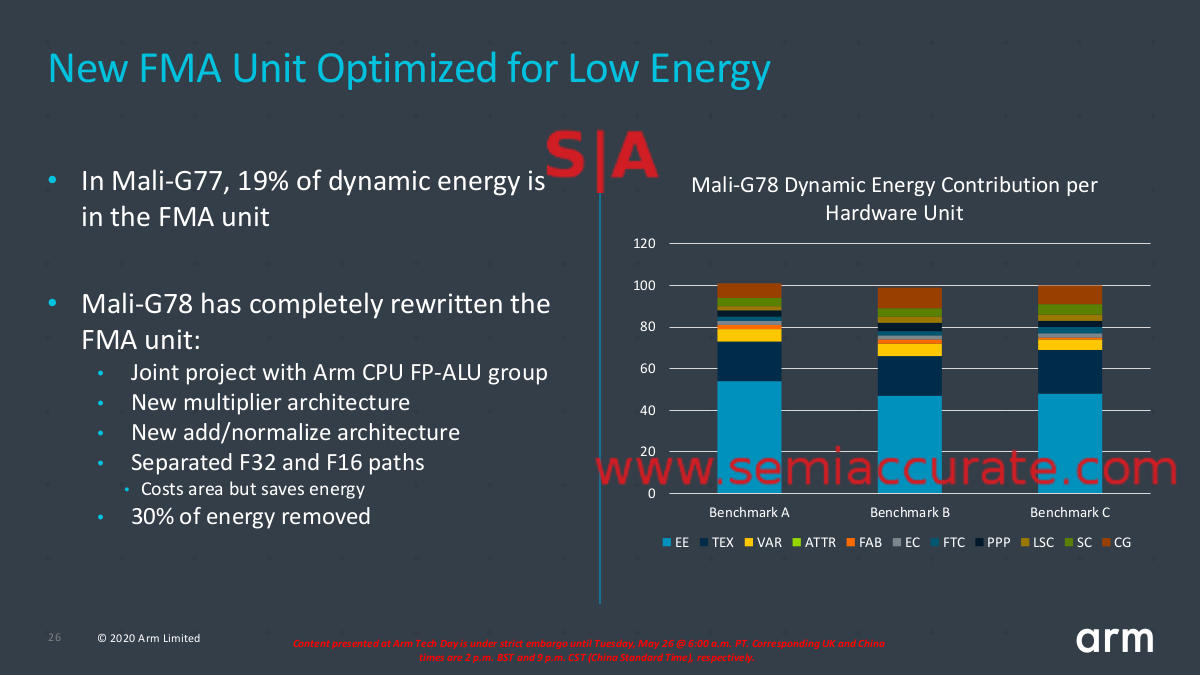
Power use is a complex thing
The multiplier and add/normalize are completely new structures, both of which are quite reasonable changes for such a major overhaul. What was a bit surprising is that ARM split up the 16b and 32b data paths on the new FMA which costs a fair bit of area. Given the energy saving though it was deemed a good tradeoff, and if the ratios are about the same on the G78, these changes on the new FMA save a net 5% of the total GPU power, a pretty astounding feat in a modern GPU.
Just when you thought it was safe to send triangles to the screen the old way, ARM once again changed things with the Mali-G78 tiler. This time the changes are a little more focused on efficiency with a claimed 8% reduction in vertex shading time for a net 2% faster execution of code on the GPU. The new architecture also has better re-use and invalidation tracking in the shader core caches which reduce internal bandwidth use by a 22%. A little here and a lot there, it all adds up.
So Mali-G78 is better, faster, and more efficient than the G77 but it can also be optioned to be much bigger, 24 shader cores to be exact. But what if you want all the goodies, API support, and next-gen features that the G78 has but you just need a small, lower performance, and cheaper device? We will admit that the market for those wanting to run complex Vulkan shaders slowly on low rez screens is a bit thin, those needing software compatibility across a range of devices is much larger.
So what do you do? If you go with a G76 or prior you are using the Bifrost architecture and that solves the smaller and cheaper bit but does not address the compatibility and features issues. G77 scales to 16 shaders, G78 to 24, but both only go down to 7 clusters. What is a smart-ish TV maker, for example, to do?

New tiers delight marketers
Enter the Mali-G68 which conveniently fits between the premium tier G7x series and the more pedestrian G5x series. This new line is called the sub-premium tier because the first 17 snarky names for it that popped into this writer’s head would probably have meant near instant and catastrophic market death for the core. It looks like ARM took the right naming path on this one.
What the G68 brings to the table is 6 shader cores, something that doesn’t sound like a big change from the 7 you can configure the G78 down to. When you stop and think about it, the Top Level, data paths, caches, and everything else on the G78 need to support 24 cores at full speed. When you configure it down to 7 cores there will be a lot of things are a underutilized. ATL can help here but you are still paying a serious area penalty for much of that unneeded functionality, and in semiconductors, area is money.
If you rebalance those non-shader bits to support 6 cores, the overall unit would choke long before you could feed 24 cores so you can’t have one device that does it all. The G68 balances out the area and cost while still offering all the goodies of the G78 core. If you are a premium TV maker that wants a line that spans from an eye-wateringly expensive 8K/240 screen to an el-cheapo 720i giveaway but wants to maintain feature compatibility and more importantly have a single code base to maintain, the G68 makes a lot of sense. Think of this sub-premium tier like FDT, it is a rebalancing based on what the market wants.
Overall the new Mali-G78 and G68 are serious updates to the Mali-G77’s Valhall architecture. Everything looks about the same from a really high level view, other than the shader cores going from 16 to 24 max, but the closer you zoom in the more things look different. Asynchronous Top Level will bring a serious step change in efficiency now and Fragment Dependency Tracking will gain more and more as software gets more complex.
From there performance and efficiency gains are more details than big bangs with the new FMA unit sitting somewhere between the two. Given the magnitude of the gains from that block, it is a pretty major detail at the very least but the rest all add up to a much more efficient GPU this time around. A 25% performance increase graphics for a new phone is a solid selling point.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026