![]() ARM is splitting it’s high end Cortex line into two series, the -A and the new -X lines. SemiAccurate thinks this is a very interesting marketing move, not to mention the underlying tech.
ARM is splitting it’s high end Cortex line into two series, the -A and the new -X lines. SemiAccurate thinks this is a very interesting marketing move, not to mention the underlying tech.
The two new cores released today are the expected Cortex-A78 and the unexpected Cortex-X1. A78 is the successor to last year’s A77 but the X1 is a new line, more of a successor to the concept of customer modifications than any particular CPU. Lets take a look at both of these cores starting out with what each is and isn’t.

Cortex-A78 vs X1 in a fight to the death!!!one!!
If you look at the slide above and come to the conclusion that the X1 is bigger and beefier than the A78, well it is. Before you question why anyone would bother with the A78 at this point, there is a good answer there too, efficiency. The two lines are aimed at very different markets, the A78 is what you would expect, energy efficiency, area efficiency, and sustained performance across a wide variety of operating conditions. Think a thermally constrained, battery powered environment like, oh, I don’t know, a phone perhaps.
The X1 on the other hand is made for performance with efficiency and area coming in as an important but secondary concern. Instead of sustained performance the X1 is aimed at peaky, bursty workloads that need performance now. If the A78 is meant for long term workloads, the X1 is a short term, single threaded benchmark special. This isn’t meant to denigrate the X1, there are a lot of workloads that need performance for a short period and then almost nothing for a long time.
Loading an app and having it run the calculations to populate the screen is a good example of this, it takes a lot of compute to get to the point where you can see that weather radar screen, then almost nothing for the next eternity or two in CPU timeframes while it waits for the user to do something. If done right the X1 could mean a much more responsive system but the main sticking point will be software.
On the other hand the A78 is meant for every day use, the sustained part of sustained performance is the key here. Games fall under the sustained performance category as would watching a movie if that wasn’t done by dedicated hardware. What core is used for what task is the open question but ARM has a good bit of experience here, remember big.little? Think of the Cortex-X1 as making it bigger.big.little and adding to the scheduler complexity.

Dynamiq is now a bit more complex
No we weren’t joking, you can put an X1 into an Dynamiq cluster in a 1+3+4 setup, presumably you can add more than one X1 if you want too, and off you go. The new core is obviously much larger than the A78 it replaces but that +15% area includes an additional 512K of L2 and 4MB of L3 cache too. In short the addition of the X1 is far from free, 15% is a serious manufacturing cost but if it makes the device feel snappier in the hands of a user it could well be worth it. If you wanted to be pedantic you could ask what else one would do with all those transistors on a 5nm process, more dark silicon isn’t as meaningful an advance.
The genesis of the X1 is that it is the first offering from the new ARM Cortex-X Custom Program, the spiritual successor to the Built on ARM Cortex Technology program which Qualcomm is the only customer of note. This time around there are six partners using the Cortex-X program to build something that differentiates their designs from the sea of other licensed ARM SoCs but ARM didn’t name them. It doesn’t take much to figure out who many of them are though.
What the X line allows them to do is push the envelope of performance a bit harder while sacrificing a little bit more power to do so, something the mainstream would not be too keen on. High end devices compete on benchmarks, mid-range and low end devices compete on price and battery life, forcing the X1’s tradeoffs on them would not be a winning move.
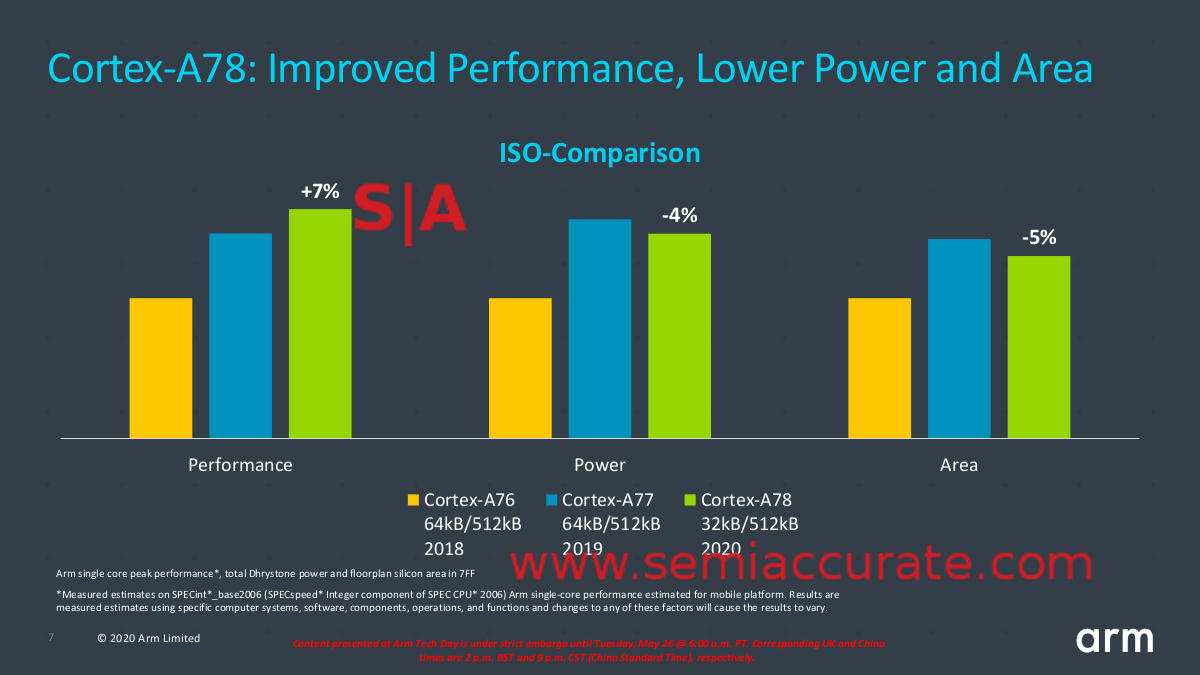
A78 vs A77
If you look at the performance of the A78, with everything held equal it is about 7% up from the A77. It uses 4% less energy than the A77 to do the same work and saves 5% area, much of which is due to the smaller 32K L1 cache. Before you wonder, the benchmarks were done with the 32K L1 not the optional 64K, that should raise performance without adding much power use should an OEM chose that design. Then we add the X1 in to the mix.
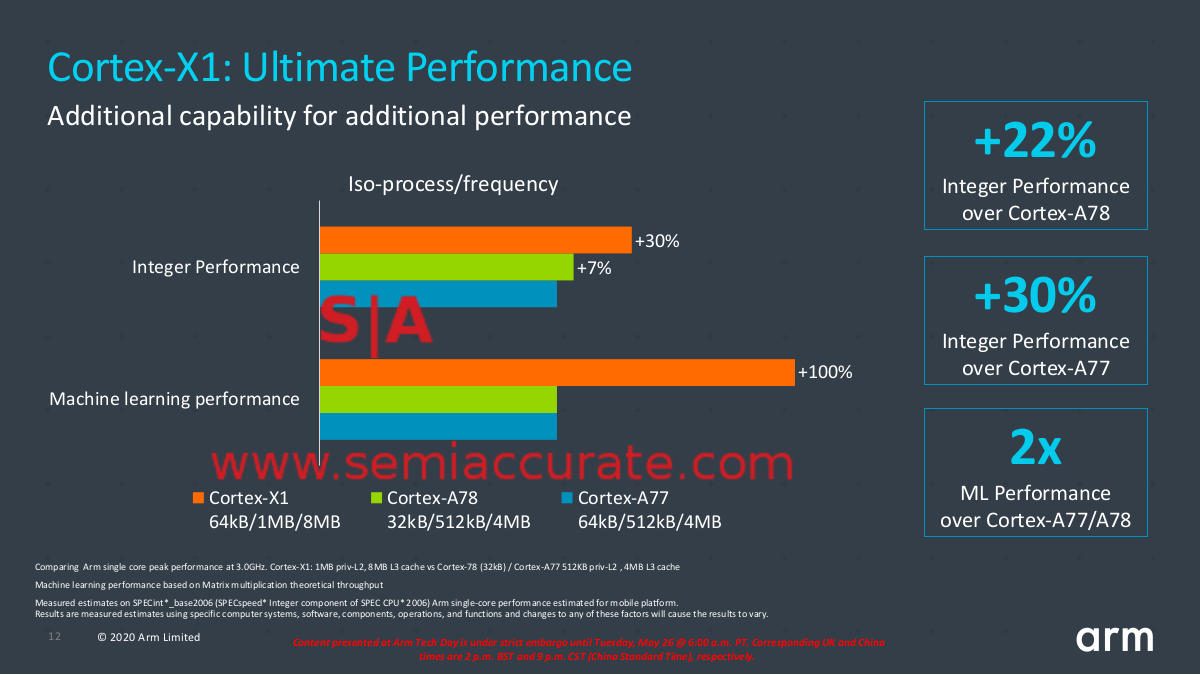
X1 vs A77 and A78
As you can see the energy and area graphs are left out but ARM is pretty clear that the X1 is not more efficient than the A78 nor is it smaller. The exact details of what the X1 brings to the table were not disclosed this time around but we expect them to be at a future date. A fair chunk of the integer performance comes from the wider issue design and larger caches but the ML Boost, pun intended, comes directly from 2x the NEON units. The X1 is about what you would expect, more performance from more area and energy.

A78 overview
Lets take a look at the A78, the new mainstream core that you will probably be using a year from now in the new crop of shiny 2021 phones. There aren’t many big bangs here, the fundamental design is similar to the A77 but as is the norm for new CPU architectures, the real advances come with the details. Also do note ARM is claiming 20% better sustained performance, a measure of energy use in a thermally constrained environment. Raw performance ‘only’ goes up by 7%, useful but not the stuff of enthusiast dreams.
On the front end the A78’s big change is to double the number of taken branches, this is our attempt at marketing hype because it goes from one to two. Prefetch bandwidth is up, L1 misses are prefetched earlier, pipelines bubbles are hidden better, and the prefetch is more accurate. As mentioned earlier the L1 caches is now available in either 32K or 64K sizes for an OEM to chose from.

A78 core diagram
There is a big change to the core itself, a second INT multiply unit was added and IMUL bandwidth was doubled to support it. More instructions can now be fused which makes the dispatch more efficient and just about everything else was upgraded. The register files are packed better meaning higher density and the OoO window and reorder buffer were both enlarged. None of these things are a killer for performance or energy use but they all add up.

A78 memory subsystem
On the memory side there is a big bang, a third AGU was added. If you look at the diagram you will see it is a load AGU not a full load/store unit but it will improve things quite a bit. Store bandwidth is doubled as is the L2 bandwidth, again both can be serious boosts to performance if used intelligently. The prefetchers were improved too with the big change being the addition of two new stride types plus a lot of unspecified secret sauce details.
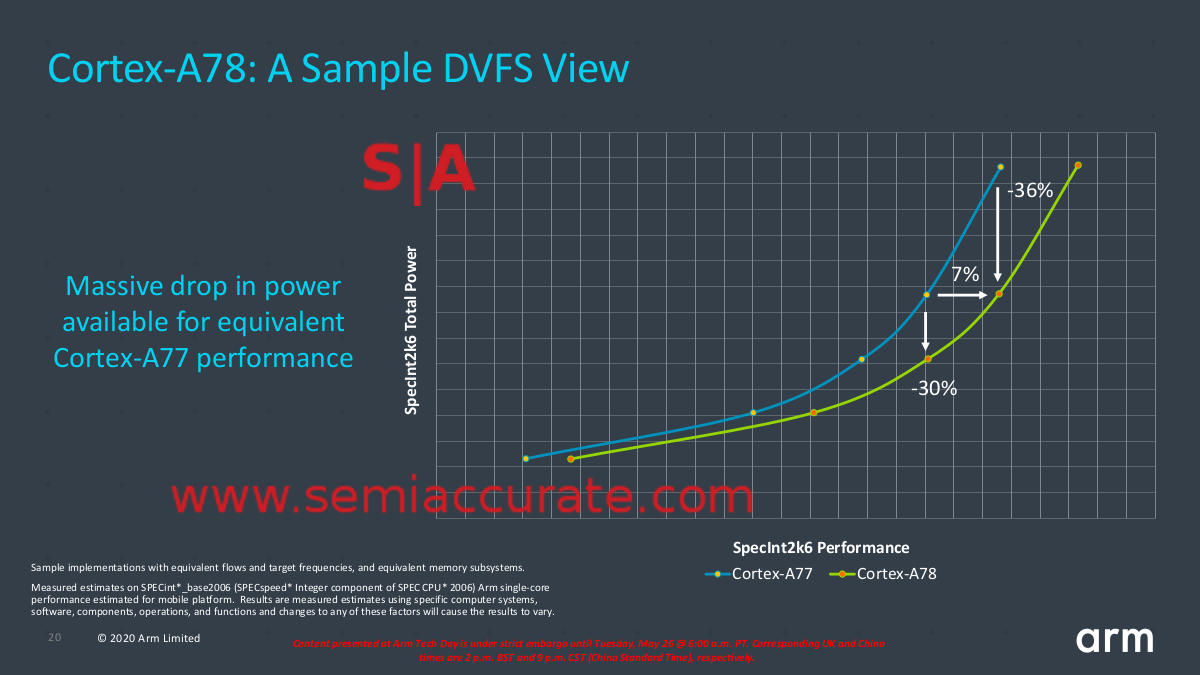
A78 vs A77 efficiency curves
As you can see the raw performance of the A78 doesn’t go up by a tremendous amount but the efficiency does. Energy use is often constrained by cooling so this is where the 20% sustained performance for the A78 number probably came from, for the same energy it can do 20% more work over the long term. Given the graphs that figure seems to be a bit conservative but the end result will be quite useful in a phone.
Moving on to the X1 we have a very different front end with a five instruction fetch and an eight instruction fetch from the Mop cache, both significantly wider than the A78. Bandwidth was obviously increased to support the additional fetches and the Mop cache is 2x larger than the A77/A78 for a total of 3K entries now. The L0-BTB was increased 50% to 96 entries as well with improved latencies in some cases.

The X1 core is very different
As you can see the X1 core is very different from the A77/A78 design, basically it adds more of everything. This is in line with peak performance being the main design goal and efficiency and area being important but secondary concerns. You can now dispatch up to eight instructions per cycle as supported by the upgraded front end and the OoO window goes from 160 to 224 instructions. The SIMD/FP bandwidth also double to a rather generous 512b (4x128b) to support the doubled NEON units. That ML Boost doesn’t come from thin air.

X1 memory subsystem
When it comes to memory, double is the operative phrase for the X1. L1D and L2 bandwidth are doubled, L2 capacity goes up by, wait for it, two, L3 can be 2x the size, and the L2-TLB is 66% bigger. Bet you weren’t expecting that one unless you actually read the slide above. If you did the 33% larger load/store window won’t be a shock either. In any case the take home message is that the memory subsystem of the X1 is up to the task of feeding those additional units.
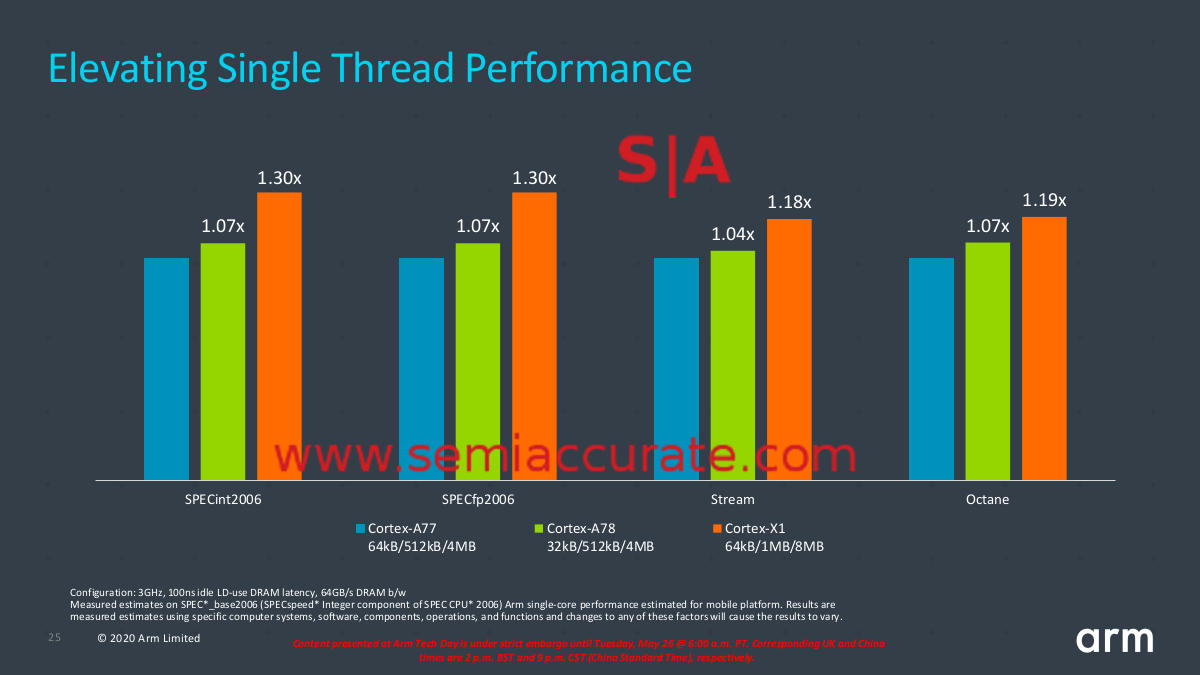
X1 vs A78 performance
As you can see those claims of 30% performance gains over the A77 are real but not an average across the board. That said the worst of those increases is >2.5x that of the A78 over the A77 so it is a substantial boost. On burst workloads the X1 core should be a notable gain as long as the scheduler doesn’t do a face-plant like early big.little attempts. Given the years of learning and testing we give ARM and it’s partners a better than average shot at getting things right out of the gate.
One last interesting bit about the X1 and the Custom-X cores in general. They are restricted to partners that joined the Custom-X program, a claimed six at the moment, but this differs from the previous semi-custom cores. The big change is in branding, the Built on ARM cores were branded by the licensee, Qualcomm’s modded A73 was called the Kryo 280 in the Snapdragon 835. This meant Qualcomm had to do all the legwork for getting a CPUID, and all the software and driver work too.
While this is hardly a problem for a quality licensee like Qualcomm, smaller vendors may struggle. With the Custom-X program, all cores like the X1 are branded as ARM cores. This will likely piss off some customers like Qualcomm but it will save them a lot of software work. Less competent vendors will be overjoyed by the change, their products will both cost less and be better supported. Consumers win but we can’t see how this will reduce friction among several high end licensees.
In the end we have two new cores, the Cortex-A78 and Cortex-X1. The big news is the updated semi-custom program, and evolution of the prior Built on ARM platform. The A78 is a solid advance and a decent evolution of the already good A77 but the X1 is a different branch aimed at different things. How well it does will depend on software support and how ARM placates licensees on an ever leveling playing field. For the consumers, things are just getting better, they are mostly immune to the politics but not the performance uplifts.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026