![]() One of the highlights of Intel’s 2020 architecture day was the outing of the 10++ process now called SuperFin. This process finally brings Intel’s 10nm process ahead of their 14nm for performance but there are still a lot of open questions on process and packaging.
One of the highlights of Intel’s 2020 architecture day was the outing of the 10++ process now called SuperFin. This process finally brings Intel’s 10nm process ahead of their 14nm for performance but there are still a lot of open questions on process and packaging.
While some people were surprised at the claimed performance and power usage for 10++/10 SuperFin, SemiAccurate told you this would happen. In early 2017. In fact so did Intel, directly, as you can see from the slide below. Since then every time Intel has come out with a 10nm part that was significantly slower than their 14nm counterparts, people acted surprised. Stupid people are one part of the process SemiAccurate can’t explain, but Intel did directly say this would happen.
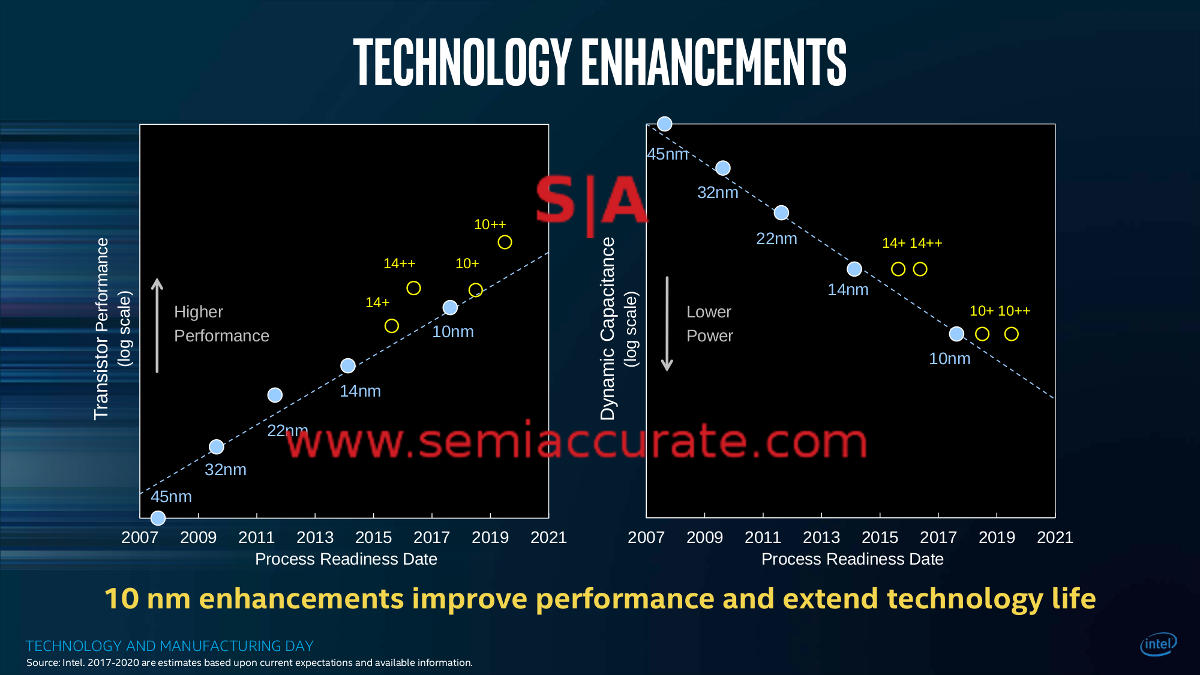
Yes they actually meant it in 2017
Anothing thing they said was that 10nm transistors, all guises, would be more efficient than 14nm, something which is also true but due to rather curious product decisions did not translate in to lower power products on the shelf. It could have but Intel… Intel… marketers… err… nice weather, eh? Why is not a topic for today but just be aware that if Intel wanted to, 10nm products could have been significantly lower power than they ended up on the shelf as, plus this would have increased yields significantly.
So today we come to 10++ and it is faster, leaks from early Tiger Lake samples have it clocking over 1GHz faster than Ice Lake could achieve, but energy use will remain an open question until that product launches. It should be better than Ice and 14nm, if for no other reason because Intel won’t have to push things as hard in order to not lose to their prior products. So how did Intel achieve this near miracle of much faster and much more efficient?
Most of the 10nm advances listed were also the big problem areas for yield on 10nm and 10+, specifically SAQP, Cobalt, and COAG. SemiAccurate detailed them here along with a few more. That was the past and Intel claims to have solved these problems, specifically COAG is now said to be over the active gate again and cobalt issues look to be much better for all foundries, not just Intel. None of this is new though, so what changed this time?

New gates and wires
Intel is claiming five big advances, three of which are listed above. Improved Gate Process and Enhanced Epitaxial Source/Drain are process and chemistry advances that weren’t detailed in the talk. While not trying to minimize the impact of these changes, SemiAccurate considers them to be incremental gains. Additional Gate Pitch is also incremental and it adds a little area but overall it is a clear win. The 10nm to 10+ changes also had improved gate pitches and better aspect ratios for the fins, something which is likely to improve with 10++, you can see those changes in the micrographs. This ability to make better gates and fins is not a trivial thing to do, don’t underestimate how hard this is, nor the advances it brings.

And the real big bang is….
The Novel Thin Barrier has some very nice effects and does reduce one of the key problems facing all tiny structures, resistance. Again this will lower power use, increase speeds or at least limit them less, and make everything better. The big bang however is the SuperMIM Capacitors, a claimed 5x increase in capacitance over earlier versions. If you are looking for the smoking gun as to how Intel clocks things faster on 10++/SuperFin, this is it. It basically allows you to push transistors faster without the negative effects of doing so, droop being a key one.
The other four advances make better use of the of the provided current, lower energy losses, and make things more efficient. Without the SuperMIM caps however, the provided current would be far lower so even if it was used much more efficiently, it begins at too low a starting point for high clocks. Together though, all five advances mean everything gets more efficient and explains the clock advances for Tiger Lake CPUs nicely. It should also mean a much more efficient end user device but once again, lets wait and see where Intel sets the numbers, that can override any process advances if things are done like Ice Lake/10+. We don’t think that mistake will be made again.
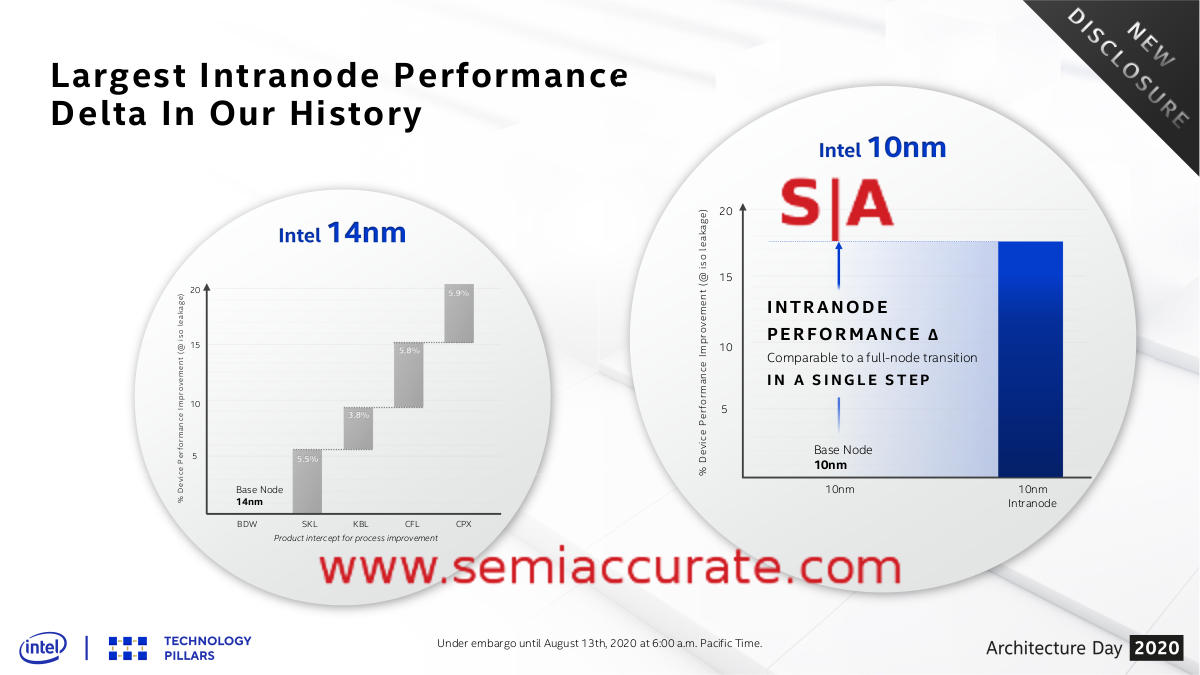
You put them all together and get…
Last up we have the numerical advances Intel is claiming, and they make for some very interesting reading. Intel is claiming ~20% better performance in aggregate for their 14nm -> 14++++nm nodes in steps of about 5% for each of the four plusses. For 10nm Intel is claiming >17% better performance from 10nm to 10++ SuperFin, something we once again believe. Unfortunately marketing seems to have forgotten that the nodes go 10nm -> 10+nm -> 10++nm/SuperFin. Since CES in January, Intel has been claiming that 10nm and 10+ are the same for some reason, they are not, not even close. We will leave it up to you to decide if this is a single 17+% leap or two ~9% leaps, either way it is significantly more than any of the 14nm steps.
So with 10++/SuperFin, Intel did exactly what they said they would over three years ago. It is faster, no question there, and it is more efficient at the transistor level. The advances are real and very cool on a technical level which should translate to very cool at the product level, pun intended. The only real question that remains is yield, something that was not discussed at Architecture Day 2020. SemiAccurate thinks it will be better than 10nm and 10+ but still nowhere near good. We should know soon enough, Tiger Lake is rumored to be launching fairly soon.
When talking about semiconductor performance, everyone focuses on the process node itself, a reasonable thing to do in times past. More recently however, packaging/advanced packaging is becoming more and more important to the point where it will likely have at least as big an effect on a device’s performance as the process itself. You only have to look as far as AMD’s Rome and the nine die it puts on a simple organic carrier to see the potential of advanced packaging.
It can make a device cheaper, more efficient, easier to manufacture (in some ways, harder in others), and shorten time to market versus traditional monolithic devices. It also enables much more flexibility in the end devices, quicker time to debug, easier fixes for problems, and many more benefits.
If done incorrectly, packaging choices can also sink a project, drive yields down, blow out costs, and any delay to a single sub-component will stop the rest dead. Tools for design and testing are also a bit rudimentary but are improving fast. In short things are not all up side but if used prudently, advanced packaging is a true game changer.
Intel is one of the leaders in advanced packaging, or at least one of the leaders in what they disclose on the topic. Their Lakefield CPU/SoC uses some very impressive techniques that no other device on the market of this high power and performance can match. EMIB, basically a slice of an interposer embedded in the organic package, brings interposer performance to devices at a potentially lower cost and higher yield. There is much debate on these points and SemiAccurate won’t wade into them for this article but lets just say they potential is there if the engineering is done right.

FPGAs are a good test vehicle
Intel is starting small in packaging and working their way up step by step. The first common EMIB device was a slightly modified AMD GPU connected to HBM via EMIB. Each successive device released, or at least announced, was more complex until we reached a multi-hop configuration on some recent Altera/Intel FPGAs. Similarly the Foveros variant of face to face(F2F) packaging found in Lakefield is fairly simple and has uses low power CPU and GPU cores. As you can see below, Intel isn’t stopping there.

Packaging technology roadmap
When you combine stacking, be it F2F or true TSV based multi-chip, you can get some pretty complex devices. Imagine putting multiple stacks on a standard organic package and connecting them with EMIB bridges. This is what Intel calls Co-EMIB. ODI or Omni-Directional Interface is a more complex Foveros variant that allows for dies of differing size to be stacked and even to have cantilevered dies. Once again this all sounds simple but doing it on a scale of microns, thousands of times per device, with commercially viable yields is a bit tougher than it may sound.


Co-EMIB and ODI are complementary
Combine this with a lot of other techniques and you get the ability to mix and match devices and chips or more likely chiplets. To do this in a sane way you need to have a common interface, Intel’s flavor is called AIB or Advanced Interface Bus. Intel is claiming over 10 3rd party AIB chiplets are available or have silicon in test so it isn’t purely theoretical. Intel says the interface is available royalty free but read the fine print before you dive in. You can see a lot more about AIB, include a generator here.

The question: Will Lego sue?
If you put all this together, what do you get? Mix and match IP blocks that scale along multiple vectors rather than a monolithic die. When Intel called this “Client 2.0” we cringed and died a little inside but they confirmed later this was just a placeholder name, thankfully we won’t be seeing it in public. As you can see the idea is you have a base die with a number of pads that can take a CPU, GPU, memory, or other accelerator.
As long as these blocks talk a common language, AIB for example, and the wiring works out, like Foveros/ODI, you can mix and match. This is a vast oversimplification, the pieces need to have a lot more work done than a common language, but the concept is actually pretty simple. Throw on some external memory and storage via EMIB, and off you go.
In the end all of these things add up to a roadmap for where Intel is headed. The process steps, the interfaces, the packaging, and much more are not meant to be discrete items like they are now, they are all going to converge at the same place. Hopefully. That is the plan anyway, and Intel is pretty intent on getting there. When they do, it should be fairly impressive.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026