![]() Today ARM is releasing a bunch of new IP with a new high-end core, the Cortex-A72, as the headliner. Also new is the Mali-T8800 GPU, Corelink CCI-500 interconnect, and POP IP on TSMC’s 16nm FinFET+ process.
Today ARM is releasing a bunch of new IP with a new high-end core, the Cortex-A72, as the headliner. Also new is the Mali-T8800 GPU, Corelink CCI-500 interconnect, and POP IP on TSMC’s 16nm FinFET+ process.
ARM tends to announce a new chip and hold off on the tech details for a later date, and today’s A72 launch was no exception. This core, formerly known as Maya, is the successor to the A57 that is just trickling out of the gate now, the Qualcomm Snapdragon 810 being the main vehicle for the moment. A72 is the next iteration of ARM’s high-end core line.
The naming change was meant to differentiate it from the A5x parts, and since it is not a member of that family, the 7 does that nicely. Like the A15/A7 combos of the dark past, you will see the A72 in a big,little combo probably with an A53 at some point in the distant future. It will be interesting to see if ARM bothers with a bespoke A7x ‘little’ chip or they just stick with the A53 until V9 family tips up.
A72 is aimed at 14/16nm FinFET processes, something that nicely explains the timing of the TSMC 16nm FinFET+ POP reveal. ARM claims that A72 on 16FF+ is 3.5x higher performance than an A15 on 28nm silicon in the same power budget. For the record they also claim an A57 at 20nm is 1.9x faster than the A15 for the same power, think almost 2x generationally. SemiAccurate asked ARM for a few more details here and they claimed that most of the gains were from architectural advances, less than half was from the process. If true those are substantial microarchitectural gains but we won’t know how until they talk tech in a few months. As usual you can also translate this into power savings at the same performance level when making a device.
A little more tech was revealed with the new Cache Coherent Interconnect 500 also known as CCI-500. This is the successor to the current CCI-400 family and is quite distinct from the CCN-500 line. CCN is a much higher-end, much more scalable, packetized interconnect that goes from 2-12 ACE clusters. That would be 8-48 cores at the moment and probably could go higher if needed.
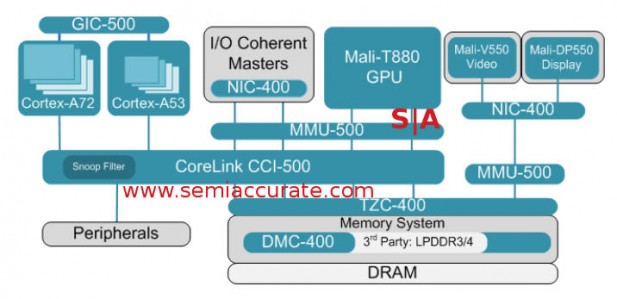
ARM’s new CCI-500 interconnect family
CCI on the other hand is aimed at mobile rather than high throughput comms usages so power and efficiency are the key goals. CCI is a crossbar instead of a ring and as of the -500 line, can scale to 4 ACE clusters, up two from CCI-400. That means you could see 16-core phones popping up with the A72 allowing user to have a full 14 cores idle instead of the current six in state of the art devices. If that isn’t progress, I can’t say what is. Think of the screen sizes this will enable!
CCI-500 is said to offer twice the bandwidth of the -400, 30% CPU memory performance increase, and do it all with less power. Some of this performance increase and scalability is due to support for four memory channels, up from two earlier. The problem there is with 16 cores and four memory channels, the bus gets a bit clogged. That is where the efficiency of CCI-500 comes in.
CCI-400 as the name suggests was cache coherent, something that scales quite poorly to large core counts without help. The CCN family had technologies to minimize snoop overhead built-in from the beginning, CCI-400 didn’t. For this reason the big addition to CCI-500 is a snoop filter, that is where a lot of the memory performance comes from as well as the increased efficiency. If you filter a snoop it saves a lot of power by not doing work. It also does not wake a core to poke at its cache contents saving quite a bit more power. In short not asking for a memory lookup and not waking slumbering cores is a good thing and both are now in the CCI line.
Next up is the new Mali-T880 GPU family, successor to last fall’s Mali-T860 GPU. The T880 is a claimed 1.8x faster than last generation’s T760 and 40% more efficient. Beating a low-end part from the last generation is no big trick for performance but if you recall the T760 was not just slower, it was architected for efficiency. Because of this, beating the T760 at efficiency is a bit of a trick, beating it handily for raw performance too is a bonus.
Much of this gain is due to an increase from six shader clusters in the T860 to eight in the T880. As they normally do, ARM aimed the two GPUs at different points on the performance vs efficiency curve so the T880 has a bunch of advancements that improve efficiency too, it isn’t just about two more clusters. Sadly those advances are not to be disclosed for a bit but we will bring them to you when we they tell us.
Those are the four major announcements for today, names, a few details, and more to follow later in the year. The A72 core and it’s updated naming structure is the new mobile king for the moment, the Mali-T880 ups ARM’s high-end GPU portfolio, CCI-500 ties it all together, and POP on TSCM 16FF+ makes it easier to make. All in all not a bad set of new bits to talk about for the next year or so.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026