![]() In nothing short of a minor miracle, Intel has decided to talk about the tech in their upcoming Knights Landing CPU. SemiAccurate is cautiously hopeful that Intel has decided to actually talk about their tech, so lets dig in.
In nothing short of a minor miracle, Intel has decided to talk about the tech in their upcoming Knights Landing CPU. SemiAccurate is cautiously hopeful that Intel has decided to actually talk about their tech, so lets dig in.
If you recall our older Knights Corner (KNC) architectural description, Knights Landing (KNL) is nothing like that. This new chip is not a collection of cores, it is a single system with one OS running across all cores. Instead of clusters of 16 cores, we now have two in a tile, rings cede to meshes although not really, kinda, and much much more. Even the core goes from a massively modified P54C to a massively modified Silvermont, quite the generational jump there.
On the surface, KNL looks like a fairly average if high-end GPU compute product. The claim is 60+ cores, Intel can’t bring themselves to admit there are 72 on the die yet, along with 3+ TF of DP FP. I’ll let you work the clocks out for yourself when you get to the vector unit width, it isn’t all that tough. On the I/O front there are 36 PCIe lanes and Omnipath connections on die.

Can you say “massive die” kiddies?
If this sounds like a massive die, you are quite right there, SemiAccurate hasn’t seen such a monster for quite a while, it dwarfs the big Nvidia GPUs for both area and DP FP performance. Using different pictures than the one above and some creative Captain-Jr-GIMP-master pixel counting skills, we came up with a die size of ~720mm^2 +/- a large margin of error. Lets just call it >700mm^2 minimum which dwarfs even the largest GPUs out there, add in the 14nm process, two nodes ahead of anyone else and it is truly a monster die.
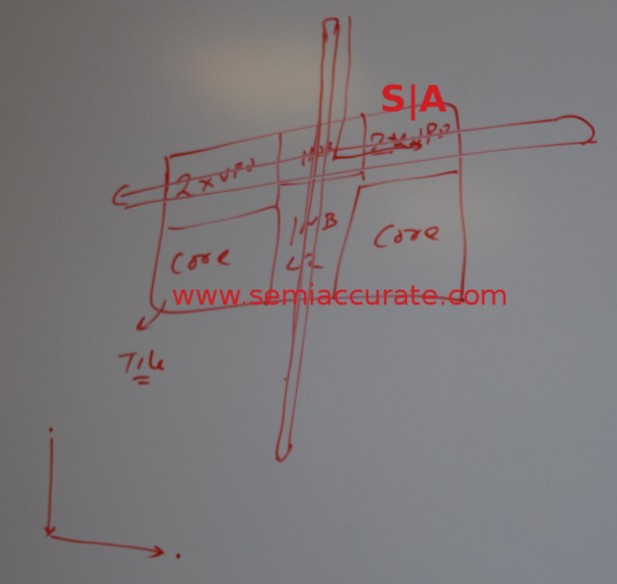
A KNL tile diagram, not to scale
The older KNC architecture was divided into four groups of 16 cores on a now familiar Intel ring interconnect. KNL does away with both, sort of, by using tiles and a mesh. The basic building block of a KNL is two cores, a 1MB L2 cache, and a ring stop. As we mentioned earlier those cores started out as a Silvermont core but have been almost completely redone.
If the shrink from 22nm to 14nm isn’t enough of a change, the basic microarchitecture has been changed quite a bit. Intel claims that the OoO logic is vastly improved on both the FP and Int sides and is now twice what Silvermont had. What exactly this means wasn’t clear but single threaded performance is up quite a bit, a claimed 3x what KNC had to offer.
More important to the workloads at hand is the VPU or vector units, two per core. Although the diagram above doesn’t make it clear, these are part of the core as well. Each one can handle 2x 512b vectors and there are obviously two cores per tile. This is a lot of math. Better yet KNL is completely Haswell ISA compatible with the exception of the TSX instruction so no more weird header flags in KN* software to get things to compile cleanly. Since Intel botched TSX badly on Haswell and it is a discoverable CPU capability, its loss shouldn’t affect anything in the real world.
The ring/mesh/bus stop is quite interesting in its own right, and quite a bit more complex than previous incarnations. Each one of the older versions supported two discrete rings that ran in opposite directions. This new, lets just call it ring stop, does quite a bit more. It sees two discrete rings, one in the X dimension and one in Y, but also sees both directions of each ring for a total of four connections. That is the long way of saying each ring passes through each stop twice but in opposite directions.
This is because the routing of KNL is quite simple and takes advantage of the gridded layout of the tiles. Each packet is injected onto the ring and moves first in the Y direction then across the X direction. If a packet needs to go ‘up’ it is injected on one side of the Y ring, ‘down’ on the other side. The same holds true for the X ring. If there is no open slot on a ring, the stop will hold the packet until there is a gap. Between this and the routing method, deadlocks are not possible and buffer overflows are extremely unlikely. At the end of the die, the rings loop around, it is not a torus structure.
Since there are 72 cores, two to a tile makes 36 tiles and the associated ring stops. How exactly this is oriented wasn’t made clear but the rectangular shape of the die strongly suggests a 4×9 layout rather than a 6×6 one. There are also a bunch of other ring stops for the Omnipath connections, PCIe root hubs, and of course the 10 memory controllers. Some of these are called out in the diagram below, the high-speed memory controllers are on the top and bottom, four per side, and the two DDR4 controllers are on the left and right. We don’t know where the I/O is located but one can assume it is evenly distributed along the left and right sides. It looks a bit like this.
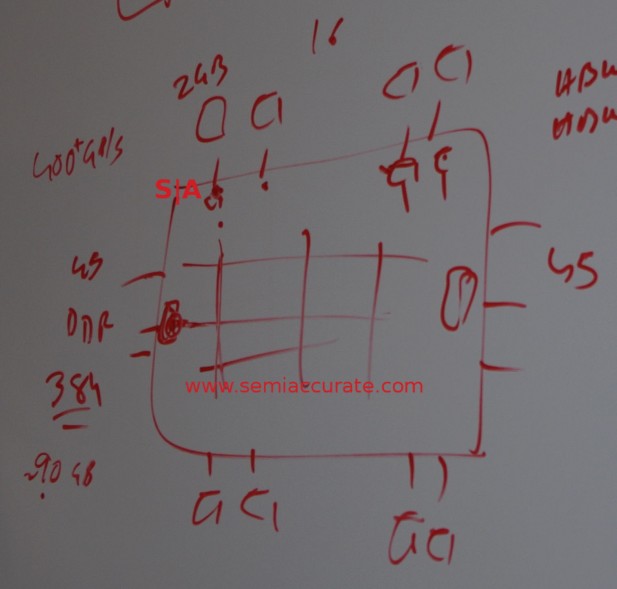
Many rings or one mesh, you decide?
That brings us to memory, all 400GB of it divided into 16GB of on-die high-speed Micron/Intel stacked memory and 384GB of plain old DDR4. There are eight high-speed memory controllers each of which can handle a 2GB stack of memory. You can see the pads for it on the package in the shot above, it has a lot of pins. Intel claims 5x Stream performance vs DDR4 so you can get a good idea of the performance of each stack.
Non-direct traffic for things like snoops goes across different physical on-chip networks but the layout is the same as the main grid. This allows the system to be one big unit but the L2 caches are discrete for each tile. They are cache coherent however, just not shared between cores like the bigger Intel cores. In this way it is similar to KNC but KNL is quite a bit more sophisticated. The L1 caches are 32K and each core does 64B, not b, loads per clock via two load ports. This means a core can load one line per clock and as a bonus has the same unaligned access logic as other modern Intel cores.
Since KNL can be run as a stand-alone system or as a co-processor on a PCIe card, this memory can be seen in three different ways depending on your specific needs. In the first the high-speed memory acts as a 16GB cache for the 384GB of DDR4, quite the expensive speedup but worth it for some workloads. Next is a flat address space where the 16GB sits on top of the DDR4 and is just addressed as more memory. Last we have direct addressing of the fastmem, Intel even has Fortran calls for this, something that will make game devs very happy. (Note: That was a joke, no need to write in, I know game devs really prefer Scheme). For the pedantic, the tags for the fastmem are kept in the memory itself so it is basically direct mapped.
Lastly we come to power management and in this case KNL can not do per-core P-states, that would require on-die VRMs which it lacks. The core and uncore can run at different frequencies but each of them are all uniform. If you think about the workloads that KNL will be running, it is likely that lots of cores ramping up and down in frequency could play havoc with workload scheduling, especially off-die scheduling when running as a co-processor.
The rest of the information, things like SKUs, models, cost, and TDPs are not being released but the chip is supposedly due for a 2H/2015 release. I would bet on Supercomputing or IDF myself but who knows which way the marketing winds will blow? There will be three types of KNLs launched in the end, PCIe card, stand alone CPU, and stand alone CPU with Omnipath. Buy one of each for the one you love, it makes the perfect late summer treat.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026