 Intel’s ring bus had a good eight year run but it all comes to an end with Skylake-EP’s mesh interconnect. While SemiAccurate can’t divulge all the details yet, there is enough in this preview to get a good idea of what is going on.
Intel’s ring bus had a good eight year run but it all comes to an end with Skylake-EP’s mesh interconnect. While SemiAccurate can’t divulge all the details yet, there is enough in this preview to get a good idea of what is going on.
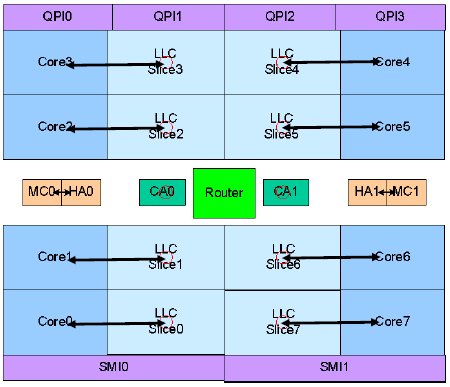
Nehalem-EX had the first ring bus
You might recall that 2009’s Becton aka Nehalem-EX was the first Intel CPU to sport a ring bus. This 8-core (at the time) monster was deemed too complex to live with a direct interconnect, shared bus, or other similar method of tying everything together. Intel’s ring bus was quite clever, bi-directional, low latency, and high bandwidth. Better yet the bulk of the area it took was in metal layers so that saved a lot of die space. It was a good solution.
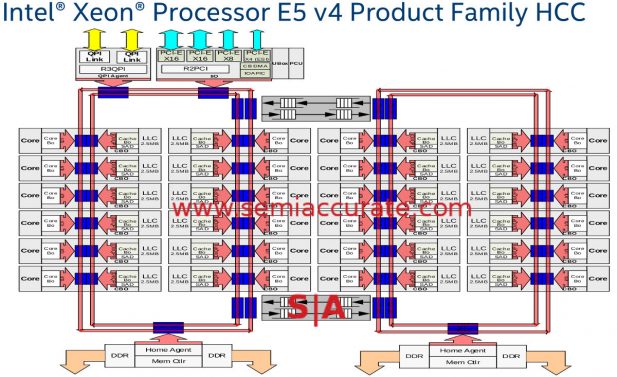
Broadwell-EP block diagram
By the time we got to Broadwell-EP things were a tad more complex with two rings and numerous bridges between them. Given that the L3 cache is distributed evenly among cores and each ring stop is shared between a core complex and an L3 slice, more rings and bridges didn’t help latency any. Since Skylake-EP is set to grow from Broadwell-EP/EX’s 22/24 cores to a rumored 28, complexity wasn’t going to go down. That brings us to Knights Landing.
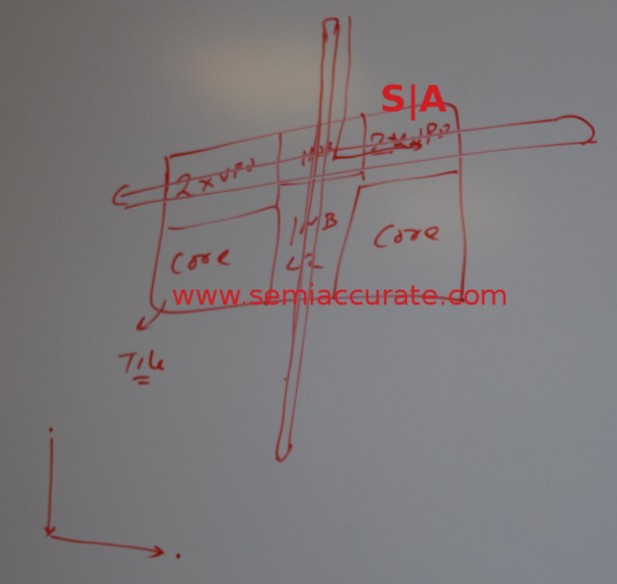
KNL mesh diagram
As you can see from the picture KNL has a bunch of rings that form a mesh. Instead of each ring stop having two directions to choose from, there are now four. Up and down is now up, down, left, and right. In KNL this supported 72 cores, a bit more than the 24 in Broadwell-EP/EX and more than is reported for Skylake-EP too. So rings scale, and that brings us to Skylake-EP.
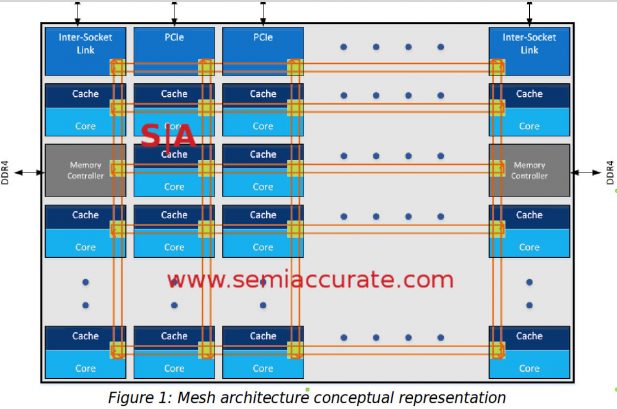
Skylake-EP’s mesh will probably resemble this
As you can see above, Skylake-EP has a mesh bus or more appropriately a lot of interconnected rings laid out like a mesh. As you can see from the official picture above, each ring does loop around at the ends, they don’t terminate. If a packet arrives at a destination and the destination for some reason doesn’t have resources to service it, the packet can theoretically loop around and keep going.
The diagram pictured above is not the layout for Skylake-EP but we can’t go into details about the differences between them for a bit. That said if the latencies remain the same for each hop, again a theoretical assumption at this point, a mesh like configuration would drop the average latencies between stops by quite a bit. If Sky’s mesh paths are computed like KNL, they will move in a single direction, it was vertical in KNL, until they get to the correct row. At that point they will turn and move horizontally until they hit the correct column, a method which reduces computation at each stop upping potential clocks quite a bit. We have no idea if Skylake uses this method but would be pretty surprised if it didn’t.
So that is the major change in architecture from Broadwell-EP to Skylake-EP, rings and bridges are replaced by meshes. Going from linear to two-dimensional travel drops the number of average hops between any two points dramatically which should show up in latencies. Given the modest increases in core counts between generations it is going to be seen as lower latencies but as KNL points out, it will allow future Xeons to scale to 3x the current core counts or more. Better yet it tremendously increases cross-sectional bandwidths on the chip. The only question left is one SemiAccurate asked Intel’s ex-CTO many years ago, what comes after meshes? His answer then, and it was more than a decade ago, was, “I don’t know”. Time to dig.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026