![]() This is Part 2 of AMD’s 2022 Financial Analyst Day, Part 1 can be found here.
This is Part 2 of AMD’s 2022 Financial Analyst Day, Part 1 can be found here.

What will come for Datacenter
Then it was Dan McNamara’s turn to take the stage and the roadmap shown was a tad sparser than what we prefer with nothing resembling new information bar one family, Siena. Sure they put Turin on the official roadmaps but we told you about that over two years ago. Yes the specs we posted have changed but that was a result of the upgrading and forking of the Genoa platform as we previously covered.
Siena is a telco focused part, you can tell that by the term “Telco” under the name on the roadmap. Yes we had to, don’t deny you would have as well. The specs given for Siena are 64 cores and performance per Watt optimized. Those hints AMD dropped seem to indicate Siena will be on the ‘small’ Genoa IOD rather than the larger 96c Genoa/Bergamo die. Telcos need lots of threads and low latency so our educated guess is the 4 DDR5 channel IOD coupled to 4x 16c Zen4c CCDs. The more pertinent part is what makes Siena a telco part rather than just a baby Bergamo? If our intuition on the layout is correct, there will be no way to add anything at the CCD level so CXL is the likely path if there is anything at all. Keep an eye out on this one, there could be interesting details under the hood.
Other tidbits in Dan’s talk were sparse but relevant. Genoa has 32MB L3 per CCD and there are obviously 12 CCDs on the device. AMD is claiming 1+ GB of L3 per socket with Genoa-X so it is safe to assume that this generation will add 64MB of L3 per CCD as well. 12*96 is 1152 so that math holds. They also claim a massive leap in AI performance which translates to the previously mentioned addition of AVX-512 and VNNI. Since AMD is not doing the software implementation, only getting to ISA parity with Intel, this feature should be widely used by software in the target markets.
From there Forrest Norrod took the ball and ran with it detailing the product lines that will come from that datacenter silicon starting with the CDNA3 based MI300 line of ‘GPUs’. We use scare quotes with that one because it is hard to justify that name for a GPU with x86 cores and FPGAs, even if some of those are likely optional. The accelerator adds Zen4 cores to the mix along with HBM for shared memory. Given the modularity of the architecture, other things like FPGAs have strongly been hinted at for future products too. The unified memory is nothing more complex than the next generation of current coherency schemes implemented on device.
Xilinx and Pensando were also mentioned because they are directly relevant to the space Forrest controls. Xilinx has a second generation of their Alveo accelerator coming in 2024 with 200Gbps support. If you are wondering why Xilinx takes so long to rev generations, they are essentially tied to the networking standards. If Gen1 can do the work at 100Gbps line rates, there is little call for more until that I/O speed increases, it is the same problem the SSD controller folk had in the early days.
Pensando also has a second generation code named Elba in the works. It is a 7nm product that does two 200Gbps links so they are a little ahead of Xilinx on this front. Until AMD opens up more about Pensando, there is little to say about this line other than ‘in production today’ doesn’t mean on the shelf soon.
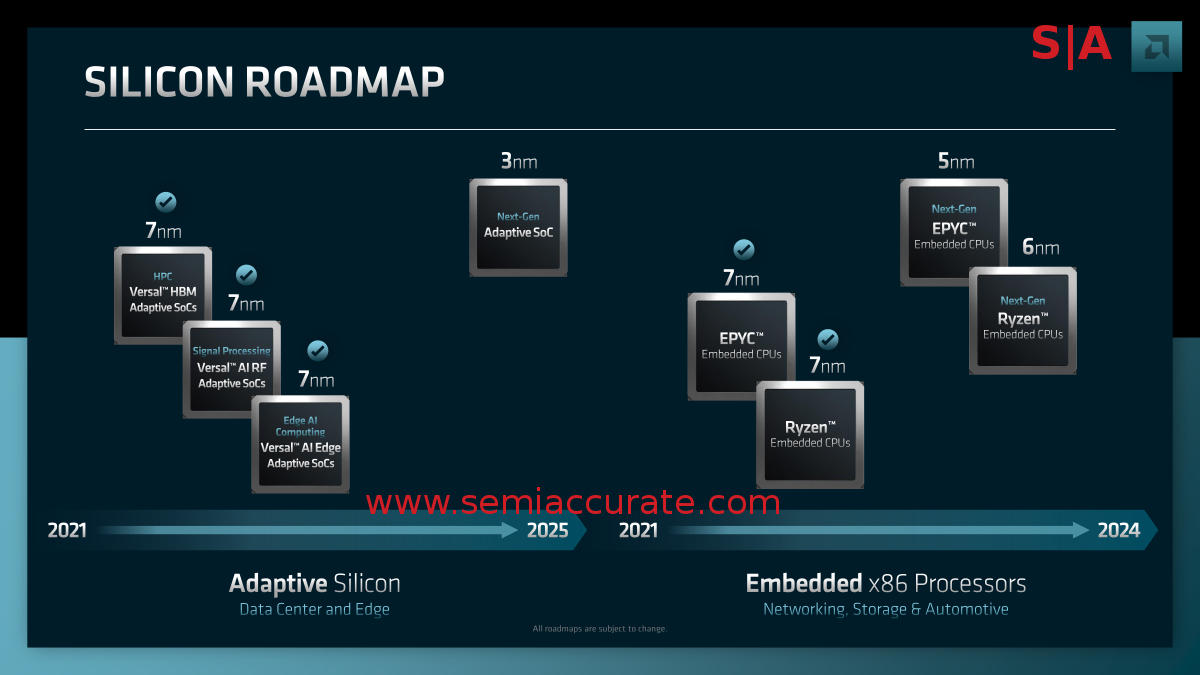
Xilinx and AMD Embedded are now embedded
That talk lead nicely into Victor Peng’s presentation about, no points if you guessed, Xilinx. And AMD embedded CPUs. The roadmap shown above isn’t all that notable other than pointing out that Xilinx is skipping over the 5nm silicon generation to jump from 7nm to 3nm. Pulling AMD embedded into the Xilinx business unit is a good idea as well, the software synergies will bring a lot better returns than keeping them under the generalized CPU side. This has long been a weak point for AMD and the company addressing it is a good step forward.
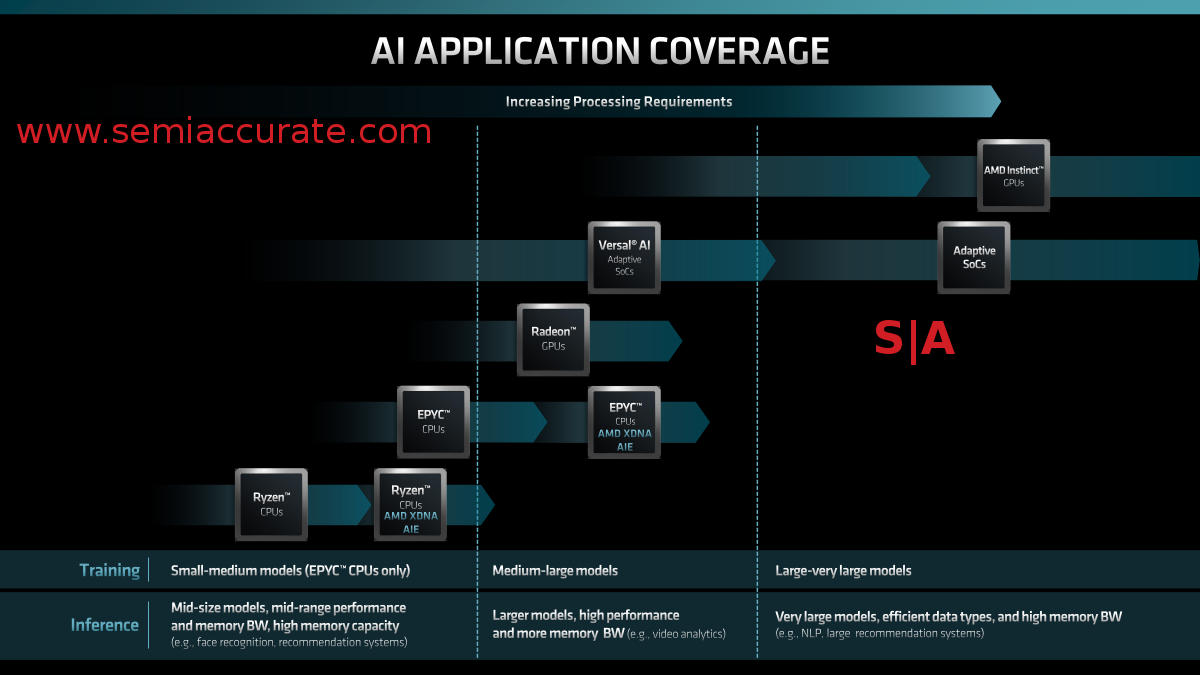
AIE is all over the place now
The talk then went to the AIE or AI Engine, something that had been referenced by many of the previous speakers. AMD is woefully behind on the AI hardware front and is in a far worse place on software. They are the only major hardware vendor not to have an AI unit in their main products, a glaring omission even if there is no real user benefit. In any case the prevalence of AIE blocks and bullet points on most upcoming product lines, especially consumer, is an attempt to rectify that problem.
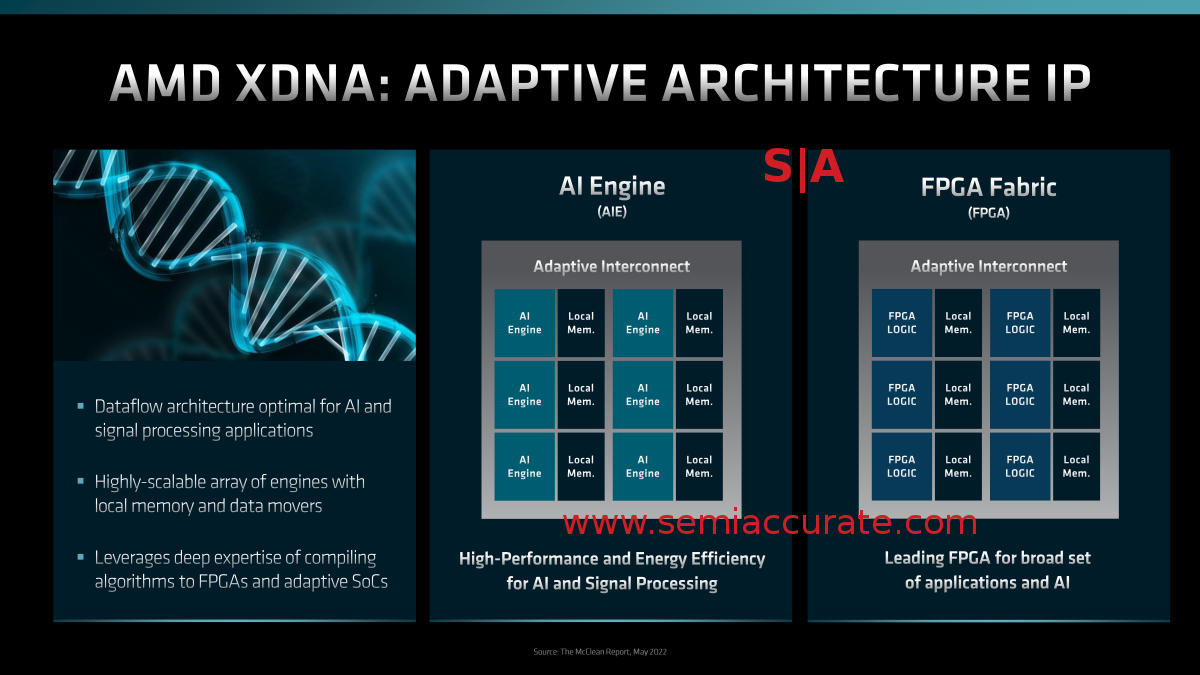
These things look alike for some reason
If you look at the diagram above, the block appears to be a small Xilinx FPGA with with AI programming hardened down to an ASIC instead of being programmed into the gates. If this inference is correct (Ha! See what we did there?) then you can expect to see similar functionality added to future products on the custom silicon side. SemiAccurate thinks this is the first attempt at AMD offering a ‘product’ to the semi-custom customers where they write the code on an FPGA before AMD hardens it and places it on their die. If this speculation is wrong, AMD really should offer this as a product, it is the best of both worlds in many ways.


AI software today and tomorrow
Possibly the most important slide of Analyst Day is the one above, the second of the two to be exact. AMD’s software efforts have been a mess for years. While they occasionally worked, finding anyone using them in production is quite an effort no matter which of the stacks you are talking about. As you can see above, AMD is taking three AI APIs and converging them into one-ish API in the vein of Intel’s OneAPI.

AI software the day after tomorrow
Before you think this is AMD catching up or even starting down the right path, do bear in mind that although the diagrams are similar to OneAPI, AMD’s offerings are for AI only, Intel’s are for everything. SemiAccurate is a big fan of the OneAPI strategy and hopes AMD is going to go fully down that path someday. For now the AMD Unified AI Stack 1.0 is a tiny piece of the puzzle. If AMD does a OneAPI-ish overarching software and tools project for everything, then you can compare the two. As you can see above, if it comes, it will be post V2.0.

Pointed roadmaps
Saeid Moshkelani had a lot to talk about on the client side, some of which was mentioned by earlier speakers and some of it new. The upcoming Phoenix Point is a decent step forward but Strix Point is the one to watch for a number of reason not mentioned by Saeid. Or by us for a bit. Sorry. In any case now you know the code names for the next few generations. Sadly none of these products are safe to deploy due to unblockable hardware backdoors. Beware, these products are not just unsafe, they seem to be intentionally compromised on the security front.
There were three numbers that AMD released for Ryzen 7000, an 8% IPC increase, a roughly 10% peak clock speed, and a >25% performance per Watt increase. We covered the performance side of things earlier but the PPW angle is interesting. That 8% and 10%, along with nebulous greater than signs come out to a nearly 20% performance gain. Given the PPW claims of >25%, that means we are looking for a rough 5% decrease in power use from Ryzen 6000 to 7000.
While this is a welcome advance but given the full shrink and the architectural gains in IPC, it isn’t nearly as impressive as SemiAccurate had hoped for. If you believe AMD’s numbers, and we unquestionably do not, you will understand why we claimed the Computex showing was underwhelming. Unsafe and incremental gains, what more could you ask for?

Who could predict this?
Then there is the roadmap of much obviousness. As you can see the consumer roadmap will mirror the datacenter one and every generation of Zen3 part will have a Zen4 based equivalent. The only new bit is the code name for Zen5 devices, Granite Point. You have to wonder where they got that crazy Granite code name from? It’s not like we told them before the project was started, saying that would be petty.
Rick Bergman had the most fun stuff to talk about because that is what he said. Then again consumer GPUs do fit that bill nicely, it is harder to talk about datacenter RAS features in the same way. In any case the basis of his talk was RDNA3, the 5nm chiplet based GPU architecture that AMD will introduce later this year. One thing that was said in the talks but not on the slides were that the RDNA3 architecture will clock much higher than RDNA2 so the trend of converging CPU and GPU clocks continues.
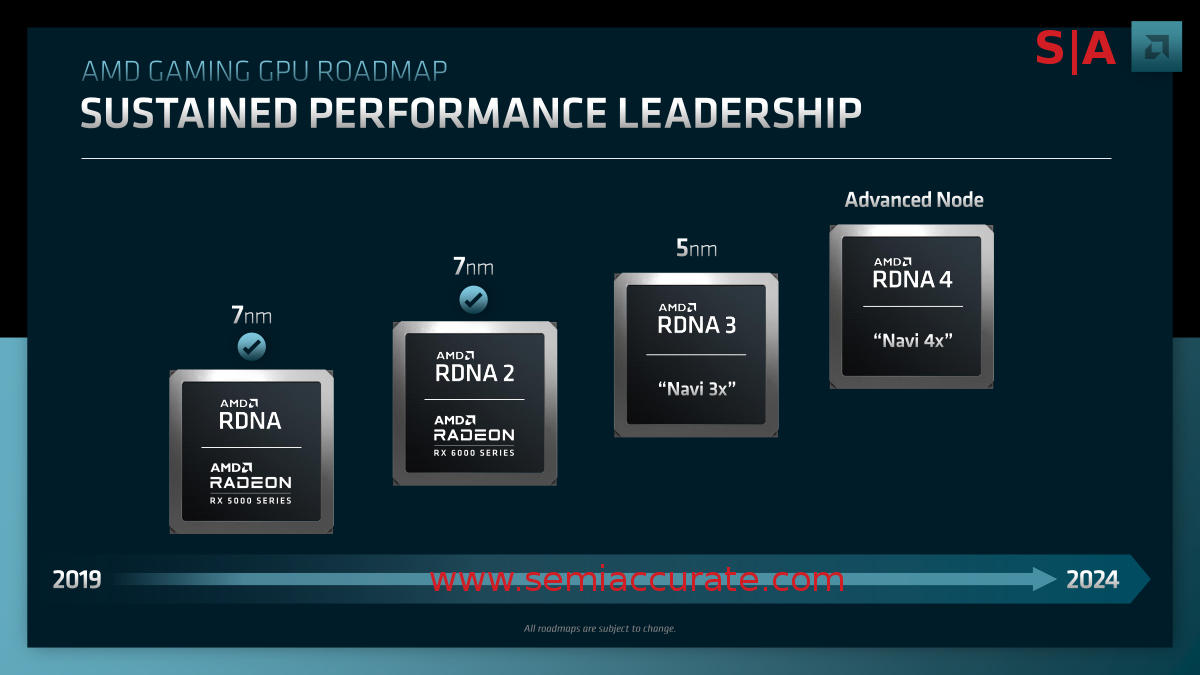
Can you count to 4?
As you can see the long awaited successor to the RDNA2 based Navi2/Radeon 6000 GPUs is the RDNA3 bearing Navi3. In a twist that everyone expected, this is followed by the RNDA4 based Navi4 line. Who knew? More importantly there was a lot of talk about custom silicon in this and many other talks. As Rick and many others pointed out over the course of Analyst Day, AMD has been doing custom silicon for years now from consoles to datacenters. Just don’t ask them what happened to that custom HP Opteron…
The last speaker barring Lisa Su’s closing statements, was CFO Devinder Kumar. Since SemiAccurate is a tech site and our financial prognostications and analyses of balance sheets is a tad lacking in depth, lets just skip those two talks and refocus on the technical side.
In the end, what did AMD show off? A lot of end user devices based on a very small set of sub-components. That is the magic of the chiplet architecture, not quite a combinatorial explosion but if you count chops, you are looking in the right direction. With GPUs coming into that world, the mix-and-match potential grows a lot larger as shown by the Computex announcement that the next big Ryzen line will have a GPU on the IOD. If you trust the official numbers, things look pretty solid. On the silicon side the path AMD chose is obviously the right one, now comes the question of whether or not they can match Intel on the next wave after chiplets.
On the down side we come back to a drum SemiAccurate has been beating for a while and AMD has been downplaying or ignoring when asked. The company has a serious problem with security on the consumer side, all their devices have an unremovable hardware backdoor that SemiAccurate feels precludes security. In the USA, consumers have paper protections but for foreign markets, are AMD’s wares salable? This question was not addressed by any of the speakers for good reason. We are closing with it because SemiAccurate feels it is a direct threat to their core business once the public understands the problem. Other than that, things look decent.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026