![]() ARM is adding two new members to its CoreLink family, say hi to the new CCN-502 and the CCN-512. These two are below and above the current lineup with one being evolutionary, the other a bigger step sideways.
ARM is adding two new members to its CoreLink family, say hi to the new CCN-502 and the CCN-512. These two are below and above the current lineup with one being evolutionary, the other a bigger step sideways.
The geeks among you might recall the last member of this interconnect family introduced, the CCN-508. This new variant ups the game from 8 clusters of 4 CPUs to 12 clusters of 4 CPUs or more simply it goes from 32 coherent cores to 48. Other than that there isn’t much difference between the -508 and -512, both have 32MB of L3, support 24 AXI4/ACE-Lite coherent I/O connections, and all the rest you know and love. The L3 is also fully ECC protected and that is not optional, neither is the end-to-end QoS and traffic prioritization.
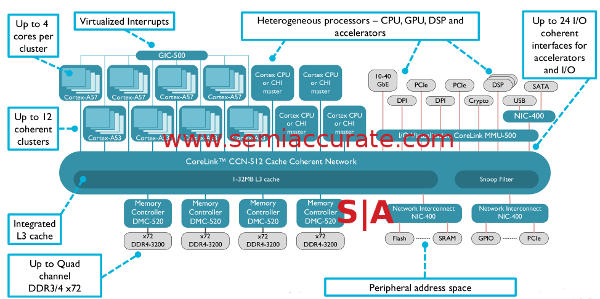
CCN-512 block diagram
It may look almost exactly the same as before but there are some major differences under the hood. First of these is that the usable bandwidth has gone way up, it now stands at 1.8Tbps for the bus. Please note this is measured, real world bandwidth, not theoretical cross-sectional bandwidth or worse yet per-hop theoretical all added up to look better than really possible. This is achieved through both higher clocks and wider lanes but ARM would not go into details on specifics. Basically the ring is more than just a CCN-508 with four more CPU cluster ports with questionable math used for PR purposes.
Memory bandwidth goes up to about 100GBps via support for DDR4/3200 with ECC. Older CCN-50x busses could also support DDR4/3200 too, ARM just never called it out on earlier iterations. Since the memory controllers are not tied to the bus directly and licensees can add whatever they want to their device, you could put anything you want there supporting whatever protocol you care about. Memory bandwidth shouldn’t be a major problem here.
CCN-502 however is a very different beast from the CCN-504 that it closely resembles in some ways. Unlike what its name might suggest, -502 supports the same four clusters of four CPUs as the -504, 16 cores total. The real differences lie in the I/O and cache capabilities, much of this was cut back and/or reworked for lower power draw and a claimed 70% area savings. ARM would not give us an estimate of the size of the respective interconnects but they did compare the CCN-502 and CCN-504 with the same 1MB cache size for fairness.
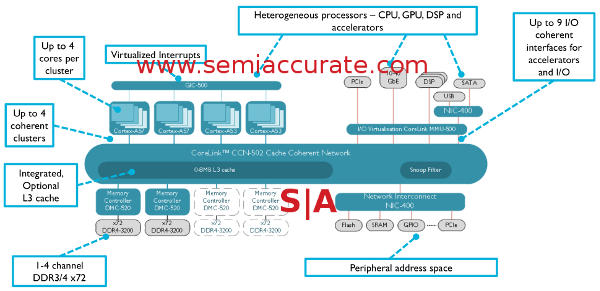
CCN-502 block diagram
First on the area savings list is the AXI4/ACE-Lite ports which go from 18 to 9 in the CCN-502. These are also reworked a bit for area savings among other things but the main chunk of that savings comes from half of them not being there. Similarly on the cache side the -504 has between 1-8MB of L3, the -502 allows 0-8MB of L3 in a system for a large potential area savings should your application not need an L3. Since the CCN-5xx line achieves coherency via the L3, we did ask if a 0MB L3 CCN-502 was coherent and the short answer is yes. The longer answer is much much longer, if we ever corner the right people over drinks and get it, a story may ensue.
A couple more technical tidbits to appease the really technical among you, that would be anyone who got this far really. First is that all of the transport layer is covered by parity on all the CCN-5xx interconnects, pretty much mandatory for anyone doing servers on this scale. The other bit is that you can run the CPU clusters asynchronously to the ring and each other if you want but that is both optional and requires bridges. If this is something you want in your design, it is doable although most users will probably just opt to turn off cores or clusters as needed.
In the end we have a new high-end and low-end interconnect from ARM, CCN-502 and CCN-502. One is aimed at the high-end CPU cluster on a chip market, the other aimed far lower for things that care about cost and power more than performance. About the only thing wrong with the whole picture is the -502’s naming and the fact that SemiAccurate was betting the CCN-516 would succeed the CCN-508, not the CCN-512. Glad we didn’t do anything stupid that involved bunny suits or anything. Again.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026