![]() Intel is cheating at benchmarks, we would say again but we have not seen any evidence they ever stopped. Although this is a strong charge to level at the company, SemiAccurate can’t find a stronger one that is as appropriate so it will stand.
Intel is cheating at benchmarks, we would say again but we have not seen any evidence they ever stopped. Although this is a strong charge to level at the company, SemiAccurate can’t find a stronger one that is as appropriate so it will stand.
Hard times lead downward:
The problem is simple, when Intel is losing at performance, they cheat on benchmarks. This isn’t done in the same way as the cell phone companies and GPU vendors do, detecting running benchmark code and changing the power or performance parameters of the hardware, Intel does it by crippling the competition. They do this through a long and complex process made possible by owning or controlling the compilers, benchmarks, libraries, and software. This time it is mainly about the libraries.
What Intel does is use the software to detect their own hardware and that of the competition by means of the processor identification string. This is “GenuineIntel” in the case of Intel, “AuthenticAMD” for AMD, and “CentaurHauls” for Centaur. There have been others in the past but these three cover the modern x86 landscape in question. Intel copyrighted their string, SemiAccurate is unsure about the other two but will assume they are as well. There is nothing wrong with detecting the CPU vendor in and of itself, in fact it can be critical to make sure some types of software runs correctly.
Tools to abuse:
Modern CPUs have widely varying instruction sets, Intel is infamous for supporting some instructions on some CPUs but not on others, fusing some ISAs off to cripple CPUs in order to add ‘value’ artificially to certain lines, and other similar feature set games. This results in a mess for coding and if software tries to run on something that does not support a specific instruction, the code obviously crashes.
To avoid this there is another set of flags called Feature Bits which do what they say and list the features of the particular CPU. You can read about the CPUID and Feature Bits here but all you really need to know is that the CPU can be queried for manufacturer and what instructions it supports. This may or may not correlate to the actual manufacturer and features on the hardware, and may or may not be nonvolatile, but it is always there on modern CPUs.
Correctly written software should not query the CPU model or family itself to determine what it is capable of because of things like the fusing games Intel plays. While assumptions like, “This CPU is newer than the one in question so it must support the things the older one did” were valid in the distant past, that is unquestionably no longer the case. You have to have your code query the exact instructions supported or it will likely crash. Why? Take a look at a single ISA, AVX-512, one of Intel’s newest extensions.
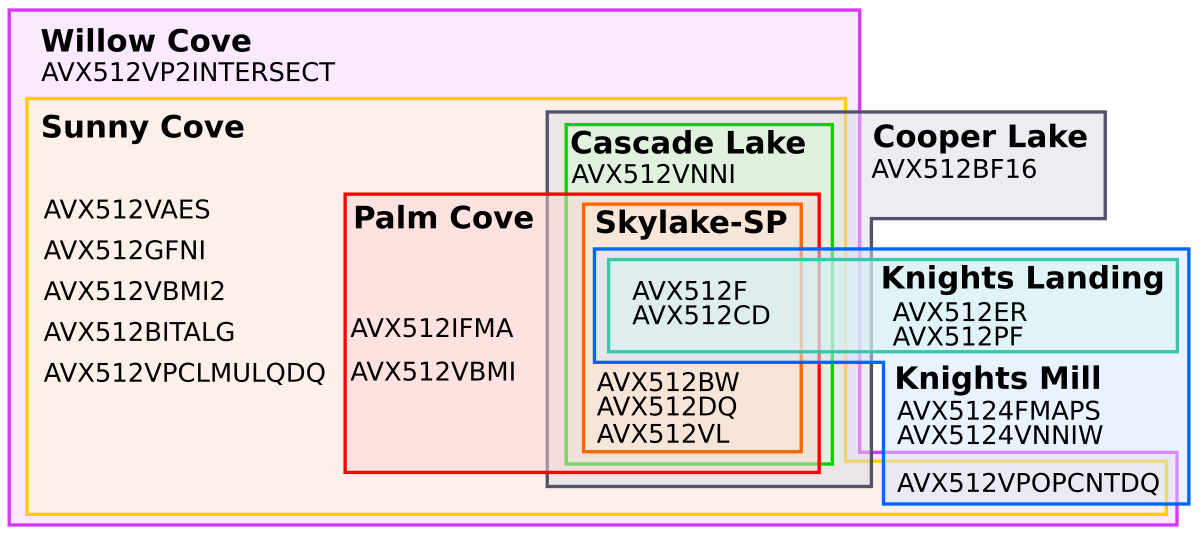
Diagram by David Schor of Wikichip, used with permission
Yup, how many variants are there? Eight. And this is just AVX-512 and it assumes there isn’t anything fused off for no reason other than to artificially segment lines. If you try to run an AVX512BITALG instruction on the upcoming Cooper Lake processors, kaboom. BFloat16 on Cooper’s successor Ice Lake will result in a similar crash. Intel is a flaming mess with regards to support for their own ISAs on modern CPUs, the only way to avoid this is to poll the CPU for exactly what instructions and features it supports and run a code path dedicated to that CPU.
The up side of this is that if you detect the features correctly and have a code path for it, the software runs at optimal speed. The down side is that you need to code for literally hundreds of variants of x86, an impossible task for a lone coder. Luckily modern compilers do this for you and modern libraries also do this as well. The resulting performance gains can be huge, think multiples or orders of magnitude in some cases, and the entire effort is more than worth the pain for anything but the most trivial code.
Detect and destroy:
This is where Intel gets sleazy. They own one of the most prominent compilers out there, ICC, and some of the most widely used math libraries as well. On top of this they strongly influence many prominent benchmarks, a charge Intel denies but also can’t explain why for years things like the mailing address of BAPCO was also the mailing address of Intel. SemiAccurate feels obligated to explain that while this was the case, it was hastily changed to a new address once exposed so all is above board now, right? The details of how Intel stacks benchmarking organizations is a bit off topic for this article but a little searching will get you the gory details. Suffice it to say that the practice is prevalent, insidious, and as active as it ever was. Ironically Intel has recently been loudly complaining in back channels that Apple is being evil by, well, doing the same thing to them with a very common modern benchmark.
With all the IDs, software control, and feature flags, what does Intel do with it? They don’t boost their own scores, they just cripple the competition. Normally these compilers, libraries, and benchmarks detect the features of the CPUs they are running on and pick a code path that is optimal for the hardware, that is correct behavior. Many of Intel’s tools do another check first however, they look at the CPUID string. If it reads, “GenuineIntel”, the code then goes on to check the features as you would expect and runs the optimal code for the hardware in question. So far so good.
The problem is that if the code detects anything other than, “GenuineIntel”, be it, “AuthenticAMD”, “CentaurHauls”, or anything else, Intel’s tools will often pick the worst possible code path and not bother to check the capabilities of the hardware at all. If the code in question is anything but the most trivial consumer application, this will usually result in, at minimum, a performance loss measured in _MULTIPLES_, not percentages. If you are running HPC or heavily numerical server code, the drop can be 10x or more. This is not an accident, it is intentionally crippling the competition.
Technically legal:
And this technically legal behavior is not new, they did it to AMD and Centaur over a decade ago. It was so blatant and so manipulative that the end result was an FTC decree that mandates the company disclose this foul behavior. For years Intel did this disclosure correctly but recently has been going out of their way to skirt the intent this mandate, something that curiously coincides with the company being handily beaten by a cheaper and better in every way AMD Epyc Rome CPU.
Of late Intel is not properly disclosing their compiler, library, and other influences, instead they are moving it to hard to find links that are not guaranteed to be there when you read the article in question. SemiAccurate’s legal skills are not sufficient to determine whether this is an actual violation of the consent decree but we can’t see how it complies, it doesn’t even seem close.
The latest incident:
The issue that prompted today’s article is simple, Intel is manipulating their math libraries to cripple AMD’s CPUs which are faster and cheaper, basically better in every way. If you run the common versions of the software out of the box using Intel’s MKL libraries as many do, a 24-core AMD Threadripper 3960x is 3.45x slower than a 14-core Intel Xeon 2175W CPU. No we are not joking, read the article by Puget System’s Dr Donald Kinghorn for the numbers we will use here.
If you take the same hardware and run the software with OpenBLAS instead of MKL, the Intel chip is 2% faster than the AMD CPU. All that was changed was the libraries from one Intel owns and controls to one that is open and detects hardware correctly. That a >2x difference in performance from software alone and shows you how and why Intel cripples the competition. That said the OpenBLAS libraries do result in significantly slower running code than the MKL version, almost 2.2x slower running on the same Intel 2175W CPU so MKL is significantly better optimized in general.
That 3.45x difference isn’t the only bit of crippling though, it gets worse. If you fake the CPUID string in software, in this case by tweaking an MKL environment variable which effectively means the code sees, “GenuineIntel” instead of, “AuthenticAMD”, MKL will suddenly process the feature bits of AMD CPUs correctly and run an optimal code path like it should. You have to set the software to debug mode and do a few other tricks that will likely be turned off in a near future build of MKL, but it does work right and avoids the competition crippling ID checks.
So what is the result if you force MKL to not artificially cripple the competition? If you guessed that the Threadripper 3960x was faster than the much more expensive Xeon 2175W, you would be right, AMD wins by about 14% if you block the competition crippling code. This means AMD goes from a 3.45x loss to a 14% win, quite the swing don’t you think? And yes it is technically legal but unquestionably unethical and sleazy. Unfortunately this is officially sanctioned behavior at Intel and has been for the tenure of at least the last three CEOs. You can read the discussion of the first public go around here. (Note: If you are wondering why competitors don’t just copy the string in their own CPUs, that is because Intel copyrighted it. This is a prime example of how to misuse a legal construct to stifle legitimate competition.)
Shout it out loud:
This vile behavior is also not uncommon. If you look at the cesspit that is Intel’s recent blogging efforts, you can see they are playing games there too. As you can see from Serve The Home’s piece on Intel and the GROMACS benchmark, this behavoir is not uncommon. This time Intel had a relatively believable set of reasons they did what they did but Patrick’s update makes it clear the main code irregularities were far from the only bits that an upstanding company wouldn’t even entertain much less do and defend.
SemiAccurate’s take on it is here, we didn’t publish and update when Intel responded due to the fact that they didn’t address the most serious points, just the ones that looked serious but in fact were not. What we mean by this is the blatant avoidance of the letter of the FTC decree while meeting the technical requirements, plus not pointing out the severe differences in the classes of hardware used but not mentioned. In short there is no up side to these ‘blogs’, if you look at any of the now hidden or obscured details, it is clear they are cheating.
Before you point out that Intel did in fact do the ‘right’ thing by manually forcing the tests in that blog to use the right code path, that is exactly the problem. Why was the software using the wrong code path again? If you are thinking it is because of library shenanigans, you might be exactly right. Intel had to go out of their way to make the software behave properly, something it is unlikely they would do in a competitive bidding process. This is the problem and Intel won’t discuss it much less admit it, just pointing out how above and beyond the call of duty they went to work around their own dirty tricks. When called out. Sometimes.
That brings us to the next facet of this problem, Intel’s sudden bent on, “real world benchmarking”. Normally SemiAccurate would consider using real software in real world tests to be a good thing. If you do it right, it really is. If you take a hex editor and look for the compiler string in actual real world software and apps that happen to use Intel’s compiler, then pick 10 common ones, is that real world? They will do the same crippling of the competition in the real world code. They will be publicly available and open for anyone to use as they will. They will also get something between a little and significant speedups if you change the CPU string as well. Fair? Ethical? Defensible? Better yet since Intel didn’t do any of the compiling, they don’t have to disclose it, it is “real world” after all.
The same holds true for stacking the boards of benchmarking organizations, picking math libraries like MKL that go above and beyond the call of duty to cripple the competition, and many more such games. Don’t stop there though, if you use many of these tricks in parallel, any one that is discovered may be masked by one or two others leading to plausible deniability! Better yet if you pick, “real world” code, you might not even have to skirt the disclosure mandates, win/win!
All together now:
In the end what it comes down to is Intel is heavily cheating on benchmarks. They do it indirectly, with plausible deniability, and often through third parties many of whom don’t realize what they are doing, most just use the free or publicly available tools. Intel will probably have a nice sounding denial of this article that avoids the main problems and adds a touch of shock and horror that someone would even intone that they do such things. That said you can run the same code and do the same tweaks for yourself, Puget Systems has the details on how in their excellent articles here and here.
If you are evaluating systems, one thing is clear however, any numbers that Intel produces should be at best evaluated in fine detail as they are potentially not valid. Worse yet what else does a company that goes to this level of detail to intentionally cripple competition do? Can the numbers gathered with their tools for their hardware be trusted even in isolation? Do their compilers and libraries detect benchmark code and spit out a number or do they actually do the work? Anything that provably does the wrong thing for financial gain in one case is unlikely to do the right thing everywhere else. Over the past two decades SemiAccurate has not had the need to question Intel’s numbers on their own hardware but their behavior of late has destroyed that trust. You would be wise to question the data too.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026