![]() Intel is really trying hard to deflect their server performance deficit with a set of new ‘information’. SemiAccurate laid out the raw numbers weeks ago, now it is time for the spin.
Intel is really trying hard to deflect their server performance deficit with a set of new ‘information’. SemiAccurate laid out the raw numbers weeks ago, now it is time for the spin.
Lets take a look at Intel’s talking points in the order they were presented, and show you what they are trying to get across and what they are hoping you don’t find out. The first of these is Cascade Lake, the ‘new’ server CPU that follows up on last year’s Purley. If you read the slide it looks like this new part is a killer, albeit with it’s branding subservient to Xpoint/Optane which is finally enabled. The sum of the data is six vague bullet points.

This is marketing not disclosure
Leadership performance is probably true depending on workload, but we will give this one to Intel. Optimized cache hierarchy, like optimized frameworks & libraries are, well, marketing BS in the grand scheme of things. The real bright spot is VNNI, the new instruction on Cascade. Other than that the chip is a bug fixed Purley, same core count, same everything. VNNI is the single item in Cascade that was not meant to be in Purley other than bug fixes.
Things get interesting when you look at the bit about higher frequencies, even if the reasons are not mentioned directly. Cascade is the same chip as Purley built on the same 14nm process with updated PDKs (14+/++/+++++++ in Intel speak), and has the same core tweaks as the consumer CPUs. Each one of these should be worth about 10% in performance ISO power, mostly due to higher clocks.
One thing Intel does not talk about is that TDP goes up, way up on Cascade by roughly 20%. Ignoring the effects on TCO for the hyperscaling set, this should also buy you another 10% in the performance category on top of the core and process mods mentioned earlier. In the semiconductor space, 10%+10%+10% does not equal 30% but it should be a substantial portion thereof.
How much more performance do you get out of Cascade over Purley? As we said months ago, 6-8% but lets be generous and call it 10%. That alone might put it under water for TCO but you could make a value argument for some cases. Once you consider the $7000 or so price increase for the top bin, ~40%, there is no justification for buying Cascade, period. <10% performance uplift is just not worth it, period. Then there is security mitigations aka bug fixes. Spectre, Meltdown, Foreshadow and the variants may be fixed in hardware.

Bulletproof lack of security
Security brings us to SGX. Intel is likely pumping this all of a sudden even though it was in Purley because of the Foreshadow attacks. You might recall Foreshadow used to be called SpecSGX because it ripped a gaping hole in Intel’s ‘impervious’ SGX security. Since SGX is a proprietary Intel technology they are obviously the only ones affected.
Why is Intel trying so hard to spin SGX now? Because if you think it is a good thing, and proprietary undocumented security mechanisms never are, then you might be less likely to question the down sides from Foreshadow. What are those downsides? You have to turn off Hyperthreading for an ~30% performance hit per core even if you don’t use SGX. No we are not joking. (Note: Read this link carefully, then go read Intel’s version if you want to see masterful spinning) SemiAccurate discussed it in more detail here too. We stand by our opinion that Intel does not take security seriously and will always put image and profit above customer safety. Buying into their proprietary security tech is borderline madness.

Cascade Lake-AP is quite vague
Then we come to the interesting new reveal, Cascade Lake-AP makes it’s debut. We told you about Cascade Lake-AP a while ago along with Cooper Lake-AP and it’s water cooler. Intel was really short on details, basically none, about Cascade-AP but we can fill in some of the blanks.
The 48C per socket means there are two chips in an MCM, XCC dies wired together via QPI links. The inter-socket links are not specified but they are likely not fully connected dies, think a square not a square with an X in the middle. In any case these monsters will be 350W meaning their TCO will be quite questionable in all but a few markets. The new socket plus the near absolute requirement for water cooling will relegate them to a niche for the reasons we described earlier. But Intel has the core count high ground. For another quarter. Cascade-AP is going to launch in 2019 as is Rome.
Then things get interesting, performance numbers. 3.4x the Linpack performance and 1.3x the Stream Triad numbers sound great right? If you have no clue about what they represent, both are mighty fine numbers. When you look at the details though, it becomes immediately clear why Intel did not put out real benchmarks for Cascade-AP.
Linpack and Stream are both trivial benchmarks that measure one bit of the system and can essentially run without stressing any other part of the device. Linpack basically measures raw number crunching and is not affected by bandwidth, cache, or much else on a system. What Linpack says is that Intel has more ALUs that AMD but nothing about whether it can use them in the real world. We knew this, the AVX implementations is some Skylake/Purley/Cascade parts are twice as wide as AMD’s Naples but in the real world they are not twice as fast. Except for some very specific and non-representative benchmarks. Guess what Intel chose here, and guess what they avoided?
The same goes for Stream Triad, it measures memory bandwidth and that’s it. AMD showed Epyc crushing Broadwell-EP at launch in 2016 because it had eight memory channels vs Intel’s four. Cascade-AP has 12 channels vs AMD’s eight so it should be 1.5x faster, the benchmark is nearly linear in performance scaling. It gets 1.3x though, remember what we said about interconnects above? I’ll bet Intel wants you to forget this slide right about now.

One X short of an own goal
So all the things Intel is claiming for Cascade-AP are things they derided about AMD when Epyc was announced. Performance leadership by lashing together cores on an MCM? More memory channels but wasn’t direct memory access ever so important? Intel’s attack slides aren’t clear on this point for some reason. Same with High Speed Interconnect, on paper Intel’s are slower AND there are less of them in Cascade Lake, and the gap grows considerably over the next 2-3 generations.
Then we come to the details about the tests. Stream was based on year old AMD numbers with year old software and systems but this is completely fair. Why? AMD hasn’t published newer versions for over a year. That said Intel should still handily win. More problematic is that Intel put a very curious memory configuration on the Epyc boxes, 16x 32GB DIMMs which could slow performance down a bit, if you are trying to tune this benchmark you would go with one DIMM per channel and use DIMMs of lower ranks for speed. The added memory is completely unnecessary.
More problematic is that Intel did not list the systems they compared it to, only the ones that Cascade ‘beat’. If you are going to make a performance claim, you better put in what you are using otherwise you look unethical. *HINT* Speaking of which, Intel used their own compilers for the AMD systems, and those compilers artificially hobbled AMD products in the past, are they still? In light of all this, you have to wonder what a competitively set up Cascade-AP system would do against a similar AMD system. Cascade would still win, but by how much? $7000 worth? (Note: The MSRP for the top Epyc part is around $4500 at the moment, that $7000 is on top of the ~$13,000 for a high end Skylake-SP)
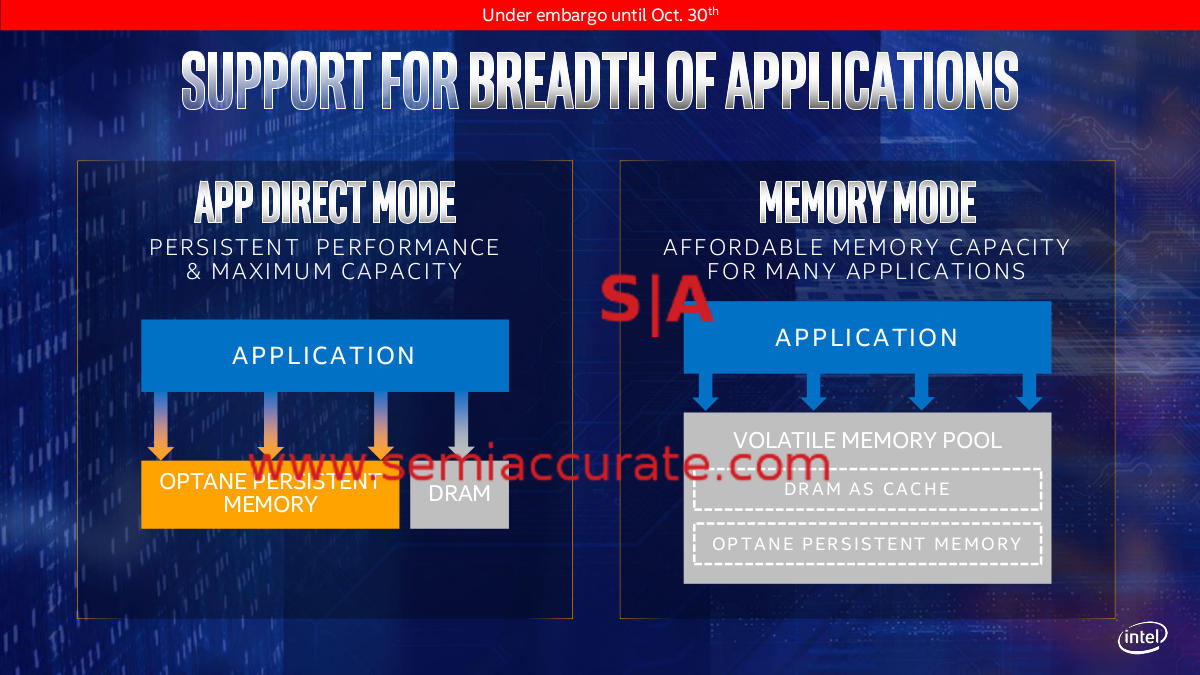
Mode set for bricking
Then we come to Optane/Xpoint, the persistent memory tech known as Apache Pass in DIMM form. It is years late, underperforming, and has never come close to promised specs, but officially it has been shipping since August 8th. Unlike DRAM, Xpoint has a known endurance rating and it is not much higher than flash, think on the order of tens of writes per day for five years. Without overprovisioning this translates to tens of thousands of writes per cell, with it, less.
If you look at the diagram on the left, App Direct Mode means software has to be aware of and written for Xpoint, basically it need to use it like fast storage rather than DRAM. The need to explicitly code for hardware instantly relegates the technology to a niche. Memory mode on the other hand fulfills the promise of Xpoint made years ago, a multiple of the capacity for a small speed hit. It looks like memory and Intel memory controllers since Romley (Note: That is not a mistake) should be able to auto-tier the different DIMMs to make it all work fairly transparently, firmware willing.
The problem SemiAccurate has with Xpoint/Apache Pass is that what is livable in an SSD format with heavy overprovisioning is not OK on a memory bus for latency reasons. Even if you have have the claimed 1000x write endurance of flash, and you have amazing flash with 100DWPD endurance, you are looking at 100K writes per day on the memory modules. How may seconds is that on a modern DDR4/2666 bus? See a problem? If you have the 20DWPD of the Xpoint SSDs and pretend you don’t lose anything when you drop overprovisioning, how many seconds is that now? 20 * 365 * 5 is not a big number.
So that is what Intel is trying to do today, point out the scant few high points of their lineup without mentioning the crippling problems. Cascade significantly underperforms the sum of it’s parts for reasons we can’t explain yet and is TCO underwater. Cascade-AP replicates all the flaws that Intel was criticizing AMD for a year ago, but isn’t nearly as elegantly executed as Epyc. On top of that it sure looks like they skewed the benchmarks and avoided disclosing the systems compared to. Security at Intel is still flat out done wrongly for the wrong reasons, and Optane is, well just say no.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026