![]() Today Intel is outing the next Atom architecture called Tremont. This small core is a very interesting beast with a few tricks SemiAccurate hasn’t seen before.
Today Intel is outing the next Atom architecture called Tremont. This small core is a very interesting beast with a few tricks SemiAccurate hasn’t seen before.
When we exclusively told you about Tremont in 2016, it was just another Atom core. The chip that is being described here is more than that, more of a flexible IP block than a strict core tied to a process like those that came before it. You might have heard it described as the little core in the Lakefield/Foveros SoC, one of four that sits beside a big Ice Lake/Sunny Cove core on that product. That oversimplifies what Tremont is and isn’t. Bear with us as we go into details, that is where the interesting parts are.

All the details
The first question you need to ask of any small core is whether it is ISA compatible with the larger cores that it often pairs with. Intel has been pretty bad about this in the past with a patchwork of capabilities spread between the Core, Atom, and Knights parts, sometimes even diverging on Xeons too. It made for a mess if you are writing software and pretty much ruled out the use of an ARM style Big/Little mechanism. If your thread migrates from one core type to another with a divergent ISA, hilarity ensues.
In this case Intel has cleaned up that ISA divergence a lot because Tremont is ISA compatible with Sunny Cove in all regards but one, AVX. Tremont doesn’t have AVX at all, not in vanilla, AVX2, or AVX-512 formats. Why? Because Tremont is aimed at integer workloads and AVX is aimed at heavy number crunching. AVX also takes up a ton of die area and required a lot of power delivery too, both of those things are not amenable to a mobile oriented, low power core. If you need AVX, the Ice Lake big core in Lakefield will wake up and run that code nicely but the OS needs to be aware of this.
In the Lakefield SoC this isn’t going to be much of an issue because all signs point to Microsoft being the one who effectively commissioned that part. If they can’t handle such a simple challenge, imagine what security holes will be like…. OK bad example. In any case this highlights a big advance in Tremont, portability. Lakefield is the first design bearing Tremont cores but not the only one. It also uses a specific configuration of Tremont, there are many options.

Tremont front end
The interesting bits start out at the top in the front end, a rather large 6-wide decoder feeds into a 4-wide allocation unit. That in turn has 10 execution ports under it and is supported by two load/store pipes. All of this sits on a bus with up to three other Tremont cores and up to 4.5MB of L2 cache. If this sounds like a pretty common recipe for a large fire breathing core, you would be right from the high level view. Once you start looking below the surface things get mighty interesting.
Notice that the queues and decoders are split in to two groups, black and grey, with a few common structure like the fetch, predict, and Icache. That is because the 6-wide decode isn’t actually a 6-wide decoder, it is two 3-wide decoders that operate in parallel. You might have also noticed a lack of structures like a micro-op cache and things related to translating x86 into sane operands, then packing or whatnot as has been the norm since the P4 days or even earlier.
This is because of cool thing #1, Tremont doesn’t use micro-ops, it executes x86 instructions natively. If you are wondering why this is a big deal you probably haven’t been paying attention to how x86 CPUs work over the last decade or two, this is pretty unique. Since you are already sitting down, we can throw the next one at you, Tremont is also not threaded. We know Atoms have gone back and forth on threading but Tremont makes it pretty clear that threaded CPUs don’t belong in this power class, something everyone but Samsung seems to have figured out.
But why two 3-wide decoders? That is where things get really interesting, they operate in parallel. SemiAccurate first jumped to the conclusion that they would each take one path on a branch, something that seems obvious but is rarely if ever worth the horrendous power cost. Tremont doesn’t do this but instead has one decoder working on a code path until it gets to a loop with a branch at the end for example.
The first decoder runs through the loop as normal while the second one starts work on the predicted branch taken so when the loop finishes, the other decoder had all the bits ready and waiting to go without a pause. After every branch taken, the system is load balanced and normal operation resumes. For obvious reasons Intel didn’t go into the whole secret sauce level details but there are probably a lot of cool tricks happening here.
This is aided by the fact that the whole front end is out of order with a 32KB Icache and can support eight outstanding misses. Predicts can run ahead, something you need for the whole second decoder scheme to work. The predictor scheme is similar to a big core rather than the Atoms that came before Tremont. The L1 predictor has a long history, 32 bytes, and has no penalty if correct. The L2 predictor is simply described as large.
Remember we were saying that Tremont is a configurable core and Lakefield is just one instantiation of that? The phrasing of up to 4.5MB of L2 is the obvious place to start that configuration but the biggest trick is that you can configure Tremont is only one 3-wide decoder if you want to save the area and power. Performance will obviously suffer but for some workloads it will be good enough. When was the last time you saw an architecture where you could halve your decoder width as an option?

Integer execution
Moving on to the instruction execution we have some interesting bits too. Integer execution is 7 wide, 3 ALU, 2 AGU, 1 jump, and 1 store. These are fed by six parallel reservations stations and backed by a huge 208 entry OoO window. Overall things were described as, “Memory and float pick two reservation stations, everything else pick one”. In short there are a lot of resources for integer execution which should help keep the pipes filled nicely and efficiently.
On the FP/vector side we have an interesting mix of units. As we mentioned earlier there are no AVX capabilities in any form so that type of vector math is right out. As befits an heavily Int oriented design, there are a lot of specialized units for doing things like crypto that may have been done on AVX units in the past. Specialized hardware will beat generalized hardware in most cases so this isn’t a bad trade for Tremont.
There are two 128b AES units on the chip which have a 4-cycle latency. Similarly there is a single instruction 256b SHA256 that also has a 4-cycle latency. The usual Intel crypto ISAs like AES-NI are supported as are Galois Field instructions (GF-NI if you care). This unit has two parallel reservation stations and three execution ports. Both can do SIMD and AES, one adds FMUL and the other FADD, the third pipe is a store.
On the memory side we have a dual load/store pipe with a generous 32KB data cache. This unit has a 3-cycle load to use latency on memory execution, quite a nice number there. The second level TLB is 1024 entry and is shared by code and data. Nothing astounding here, everything just looks well optimized for the task at hand.
Going back to the theme of configurability we come to the memory subsystem. Earlier we said the L2 was configurable and it can range from 1.5-4.5MB. If there is a core turned off the L2 is not affected in case you are wondering. Each core is on a separate power plane as you would expect from a power optimized design like this. The last level of cache, L2 in this case, can be configured to be inclusive or non-inclusive, a big hint that Intel plans to use this core across multiple designs for multiple markets.
More interesting is that the Tremont core supports Intel’s cache partitioning technology first seen in in the big Xeons a few years ago. This allows the cache to be partitioned for QoS or other reasons and works especially well in multi-tenant scenarios. Now called Resource Director Technology, it can prioritize on many more vectors and enforce memory bandwidth restrictions. SemiAccurate feels that the bandwidth side is much more appropriate to the tasks Tremont will be put to than the Cache QoS features.
There are two more technologies in this core that are worth talking about, accelerators and memory encryption. There are three instructions that fall under the banner of Accelerator Interfacing Instructions, TPAUSE, UMONITOR, and MoveDR, in Tremont. They aren’t new per se but the work better and more efficiently now again because of the intended workloads for Tremont.
The last bit is Total Memory Encryption and does about what it sounds like it should do. This is a good thing, a very good thing, that has been a glaring hole in the Intel cores for far too long. Intel’s security infrastructure has been woeful or worse but TME is a move in the right direction. Unfortunately it is only a fraction of the way to where they need to be, AMD’s Naples did this an much much more years ago, the recent Rome Epyc added significantly to that. Hopefully Intel will accelerate the addition of security features, they need it.
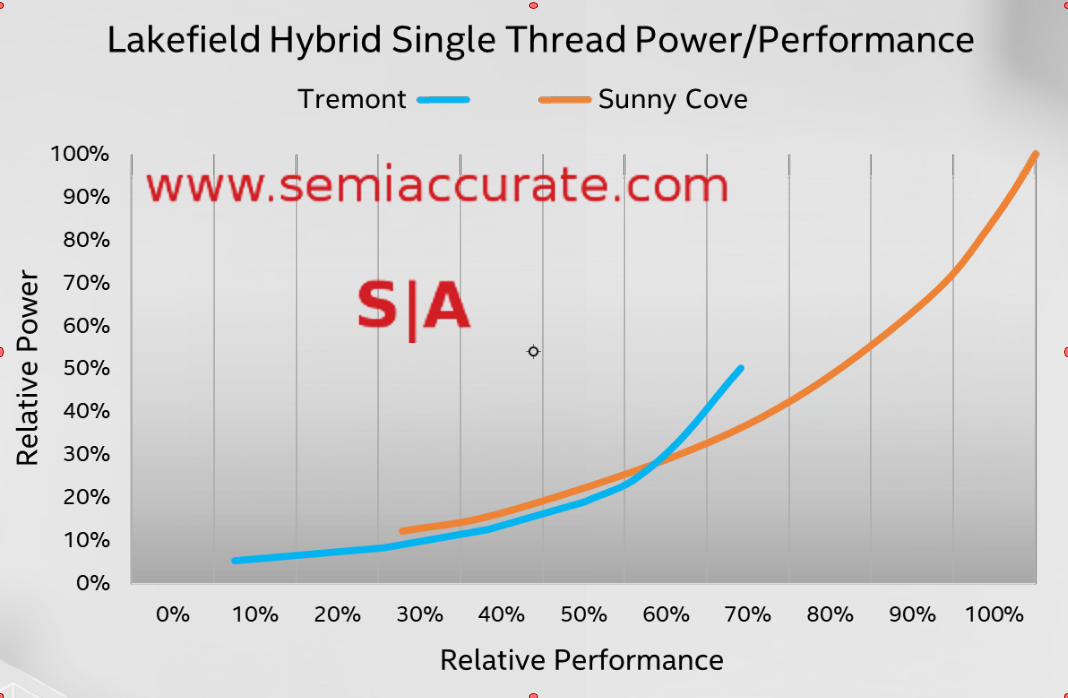 Graded on a curve
Graded on a curve
So how does Tremont perform? It has a claimed 30% IPC increase over Goldmont+ which is a major step, 3x what Intel has delivered on the big cores of late. While no one is under any illusions that the little cores will beat the big cores in outright single threaded performance but the above slide shows that they are able to hold their own across a solid range of performance.
In the end what do we have? About what Intel said it was making, a small, low power core that will excel at integer work and not fall over on other workloads like some low power architectures. It mostly cleans up the ISA mess Intel has had for far too long and introduces one desperately needed security feature. On top of that there are a lot of really neat tricks that SemiAccurate hasn’t seen before which make Tremont a very interesting core overall.S|A
Charlie Demerjian
Latest posts by Charlie Demerjian (see all)
- Intel Bumps Xeon Memory Speeds - Jul 20, 2026
- Qualcomm’s 2026 Investor Day Has Hidden Goodies - Jul 15, 2026
- Phison Phudges The Numbers… In A Good Way - Jun 24, 2026
- Who Are The Qualcomm Enterprise Customers? - Jun 23, 2026
- Innodisk Adds 10GbE To Useless M.2 Slots - Jun 19, 2026